本文转自Jerryshao Blog
随着big data的发展,人们对大数据的处理要求也越来越高,传统的MapReduce等批处理框架在某些特定领域(如实时用户推荐,用户行为分析)已经无法满足人们对实时性的需求。因此诞生了一批如S4,Storm这样的流式的、实时的计算框架。本文介绍的Spark Streaming也正是一个这样的流式计算框架。
What is Spark Streaming
作为UC Berkeley云计算software stack的一部分,Spark Streaming是建立在Spark上的应用框架,利用Spark的底层框架作为其执行基础,并在其上构建了DStream的行为抽象。利用DStream所提供的api,用户可以在数据流上实时进行count,join,aggregate等操作。
A Spark Streaming application is very similar to a Spark application; it consists of a driver program that runs the user’s main function and continuous executes various parallel operations on input streams of data. The main abstraction Spark Streaming provides is a discretized stream (DStream), which is a continuous sequence of RDDs (distributed collections of elements) representing a continuous stream of data. DStreams can be created from live incoming data (such as data from a socket, Kafka, etc.) or can be generated by transformong existing DStreams using parallel operators like map, reduce, and window.
How to Use Spark Streaming
作为构建于Spark之上的应用框架,Spark Streaming承袭了Spark的编程风格,对于了解Spark的用户来说能够快速地上手。接下来以word count为例来介绍Spark Streaming的使用方式:
import spark.streaming.{Seconds, StreamingContext}
import spark.streaming.StreamingContext._
...
// Create the context and set up a network input stream to receive from a host:port
val ssc = new StreamingContext(args(0), "NetworkWordCount", Seconds(1))
val lines = ssc.socketTextStream(args(1), args(2).toInt)
// Split the lines into words, count them, and print some of the counts on the master
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
-
创建
StreamingContext对象同Spark初始需要创建
SparkContext对象一样,使用Spark Streaming就需要创建StreamingContext对象。创建StreamingContext对象所需的参数与SparkContext基本一致,包括指明master,设定名称(如NetworkWordCount)。需要注意的是参数Seconds(1),Spark Streaming需要指定处理数据的时间间隔,如上例所示的1s,那么Spark Streaming会以1s为时间窗口进行数据处理。此参数需要根据用户的需求和集群的处理能力进行适当的设置。 -
创建
InputDStream如同Storm的
Spout,Spark Streaming需要指明数据源。如上例所示的socketTextStream,Spark Streaming以socket连接作为数据源读取数据。当然Spark Streaming支持多种不同的数据源,包括kafkaStream,flumeStream,fileStream,networkStream等。 -
操作
DStream对于从数据源得到的
DStream,用户可以在其基础上进行各种操作,如上例所示的操作就是一个典型的word count执行流程:对于当前时间窗口内从数据源得到的数据首先进行分割,然后利用MapReduce算法映射和计算,当然最后还有print()输出结果。 -
启动Spark Streaming
之前所作的所有步骤只是创建了执行流程,程序没有真正连接上数据源,也没有对数据进行任何操作,只是设定好了所有的执行计划,当
ssc.start()启动后程序才真正进行所有预期的操作。
至此对于Spark Streaming的如何使用有了一个大概的印象,接下来我们来探究一下Spark Streaming背后的代码。
Spark Streaming 源码分析#
StreamingContext
Spark Streaming使用StreamingContext提供对外接口,用户可以使用StreamingContext提供的api来构建自己的Spark Streaming应用程序。
StreamingContext内部维护SparkContext实例,通过SparkContext进行RDD的操作。- 在实例化
StreamingContext时需要指定batchDuration,用来指示Spark Streaming recurring job的重复时间。 StreamingContext提供了多种不同的接口,可以从多种数据源创建DStream。StreamingContext提供了起停streaming job的api。
DStream
Spark Streaming是建立在Spark基础上的,它封装了Spark的RDD并在其上抽象了流式的数据表现形式DStream:
A Discretized Stream (DStream), the basic abstraction in Spark Streaming, is a continuous sequence of RDDs (of the same type) representing a continuous stream of data. DStreams can either be created from live data (such as, data from HDFS, Kafka or Flume) or it can be generated by transformation existing DStreams using operations such as
map,windowandreduceByKeyAndWindow. While a Spark Streaming program is running, each DStream periodically generates a RDD, either from live data or by transforming the RDD generated by a parent DStream.
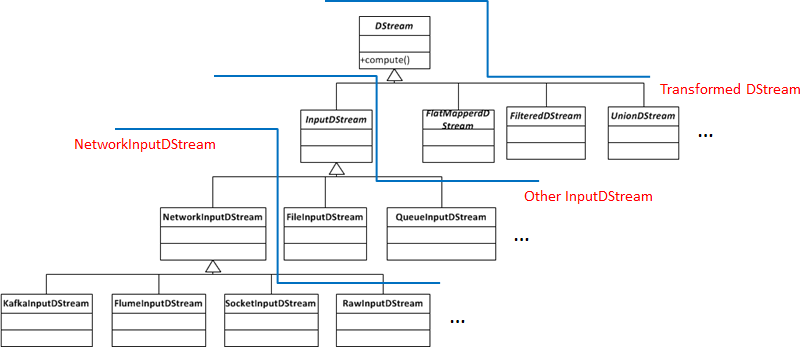
DStream内部主要结构如下所示:
abstract class DStream[T: ClassManifest] (
@transient protected[streaming] var ssc: StreamingContext
) extends Serializable with Logging {
initLogging()
// =======================================================================
// Methods that should be implemented by subclasses of DStream
// =======================================================================
/** Time interval after which the DStream generates a RDD */
def slideDuration: Duration
/** List of parent DStreams on which this DStream depends on */
def dependencies: List[DStream[_]]
/** Method that generates a RDD for the given time */
/** DStream的核心函数,每一个继承于此的子类都需要实现此compute()函数。而根据不同的
DStream, compute()函数都需要实现其特定功能,而计算的结果则是返回计算好的RDD*/
def compute (validTime: Time): Option[RDD[T]]
// =======================================================================
// Methods and fields available on all DStreams
// =======================================================================
// RDDs generated, marked as protected[streaming] so that testsuites can access it
/** 每一个DStream内部维护的RDD HashMap,DStream本质上封装了一组以Time为key的RDD,而对于
DStream的各种操作在内部映射为对RDD的操作 */
@transient
protected[streaming] var generatedRDDs = new HashMap[Time, RDD[T]] ()
// Time zero for the DStream
protected[streaming] var zeroTime: Time = null
// Duration for which the DStream will remember each RDD created
protected[streaming] var rememberDuration: Duration = null
// Storage level of the RDDs in the stream
protected[streaming] var storageLevel: StorageLevel = StorageLevel.NONE
// Checkpoint details
protected[streaming] val mustCheckpoint = false
protected[streaming] var checkpointDuration: Duration = null
protected[streaming] val checkpointData = new DStreamCheckpointData(this)
// Reference to whole DStream graph
/** 所有的DStream都注册到DStreamGraph中,调用DStreamGraph来执行所有的DStream和所有的dependencies */
protected[streaming] var graph: DStreamGraph = null
protected[streaming] def isInitialized = (zeroTime != null)
// Duration for which the DStream requires its parent DStream to remember each RDD created
protected[streaming] def parentRememberDuration = rememberDuration
...
DStream在内部维护了一组时间序列的RDD,对于DStream的transformation和output在内部都转化为对于RDD的transformation和output。
下面来看一下对于DStream的计算是如何映射到对于RDD的计算上去的。
protected[streaming] def getOrCompute(time: Time): Option[RDD[T]] = {
// If this DStream was not initialized (i.e., zeroTime not set), then do it
// If RDD was already generated, then retrieve it from HashMap
generatedRDDs.get(time) match {
// If an RDD was already generated and is being reused, then
// probably all RDDs in this DStream will be reused and hence should be cached
case Some(oldRDD) => Some(oldRDD)
// if RDD was not generated, and if the time is valid
// (based on sliding time of this DStream), then generate the RDD
case None => {
if (isTimeValid(time)) {
/** 对于每一次的计算,DStream会调用子类所实现的compute()函数来计算产生新的RDD */
compute(time) match {
case Some(newRDD) =>
if (storageLevel != StorageLevel.NONE) {
newRDD.persist(storageLevel)
logInfo("Persisting RDD " + newRDD.id + " for time " + time + " to " + storageLevel + " at time " + time)
}
if (checkpointDuration != null && (time - zeroTime).isMultipleOf (checkpointDuration)) {
newRDD.checkpoint()
logInfo("Marking RDD " + newRDD.id + " for time " + time + " for checkpointing at time " + time)
}
/** 新产生的RDD会放入Hash Map中 */
generatedRDDs.put(time, newRDD)
Some(newRDD)
case None =>
None
}
} else {
None
}
}
}
}
通过每次提交的job,调用getOrCompute()来计算:
protected[streaming] def generateJob(time: Time): Option[Job] = {
getOrCompute(time) match {
case Some(rdd) => {
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }
context.sparkContext.runJob(rdd, emptyFunc)
}
Some(new Job(time, jobFunc))
}
case None => None
}
}
Job & Scheduler
从DStream可知,在调用generateJob()时,DStream会通过getOrCompute()函数来计算或是转换DStream,那么Spark Streaming会在何时调用generateJob()呢?
在实例化StreamingContext时,StreamingContext会要求用户设置batchDuration,而batchDuration则指明了recurring job的重复时间,在每个batchDuration到来时都会产生一个新的job来计算DStream,从Scheduler的代码里可以看到:
val clockClass = System.getProperty("spark.streaming.clock", "spark.streaming.util.SystemClock")
val clock = Class.forName(clockClass).newInstance().asInstanceOf[Clock]
/** Spark streaming在Scheduler内部创建了recurring timer,recurring timer的超时时间
则是用户设置的batchDuration,在超时后调用Scheduler的generateJob */
val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds,
longTime => generateJobs(new Time(longTime)))
generateJobs()的代码如下所示,Scheduler的generateJobs()会调用DStreamGraph的generateJobs,并对于每一个job使用JobManager来run job。
def generateJobs(time: Time) {
SparkEnv.set(ssc.env)
logInfo("\n-----------------------------------------------------\n")
graph.generateJobs(time).foreach(jobManager.runJob)
latestTime = time
doCheckpoint(time)
}
在DStreamGraph中,generateJobs()如下所示:
def generateJobs(time: Time): Seq[Job] = {
this.synchronized {
logInfo("Generating jobs for time " + time)
val jobs = outputStreams.flatMap(outputStream => outputStream.generateJob(time))
logInfo("Generated " + jobs.length + " jobs for time " + time)
jobs
}
}
对于每一个outputStream调用generateJob()来转换或计算DStream,output的计算会依赖于dependecy的计算,因此最后会对所有dependency都进行计算,得出最后的outputStream。
而所有的这些操作,都在调用StreamingContext的启动函数后进行执行。
def start() {
if (checkpointDir != null && checkpointDuration == null && graph != null) {
checkpointDuration = graph.batchDuration
}
validate()
/** StreamingContext注册和启动所有的input stream */
val networkInputStreams = graph.getInputStreams().filter(s => s match {
case n: NetworkInputDStream[_] => true
case _ => false
}).map(_.asInstanceOf[NetworkInputDStream[_]]).toArray
if (networkInputStreams.length > 0) {
// Start the network input tracker (must start before receivers)
networkInputTracker = new NetworkInputTracker(this, networkInputStreams)
networkInputTracker.start()
}
Thread.sleep(1000)
// 启动scheduler进行streaming的操作
scheduler = new Scheduler(this)
scheduler.start()
}
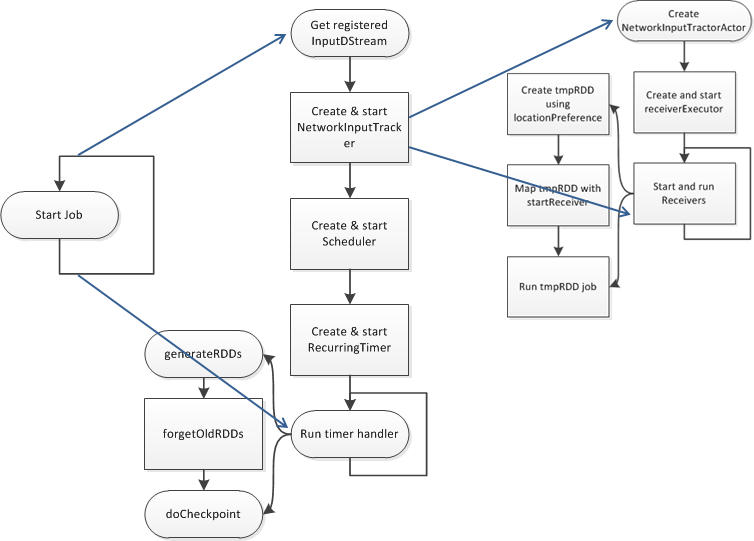
至此,对于Spark Streaming的使用和内部结构应该有了一个基本的了解,以一副Spark Streaming启动后的流程图来结束这篇文章。