本文转自Jerryshao Blog
Overview
本文章主要对Spark,Spark的基本架构和重要模块作基本介绍,文章不会涉及Spark的安装部署以及使用,对此可以参考Spark官方文档。
What is Spark
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce 框架,都是基于map reduce算法所实现的分布式计算框架,拥有Hadoop MapReduce所具有的 优点;不同于MapReduce的是Job中间输出和结果可以保存在内存中,而不需要读写HDFS,因 此Spark能更好地适用于machine learning等需要迭代的map reduce算法。
Spark is an open source cluster computing system that aims to make data analytics fast — both fast to run and fast to write.
To run programs faster, Spark provides primitives for in-memory cluster computing: your job can load data into memory and query it repeatedly much quicker than with disk-based systems like Hadoop MapReduce.
To make programming faster, Spark provides clean, concise APIs in Scala, Java and Python. You can also use Spark interactively from the Scala and Python shells to rapidly query big datasets.
Spark Architecture
援引@JerryLead的系统架构图作为Spark整体结构的一个 birdview:
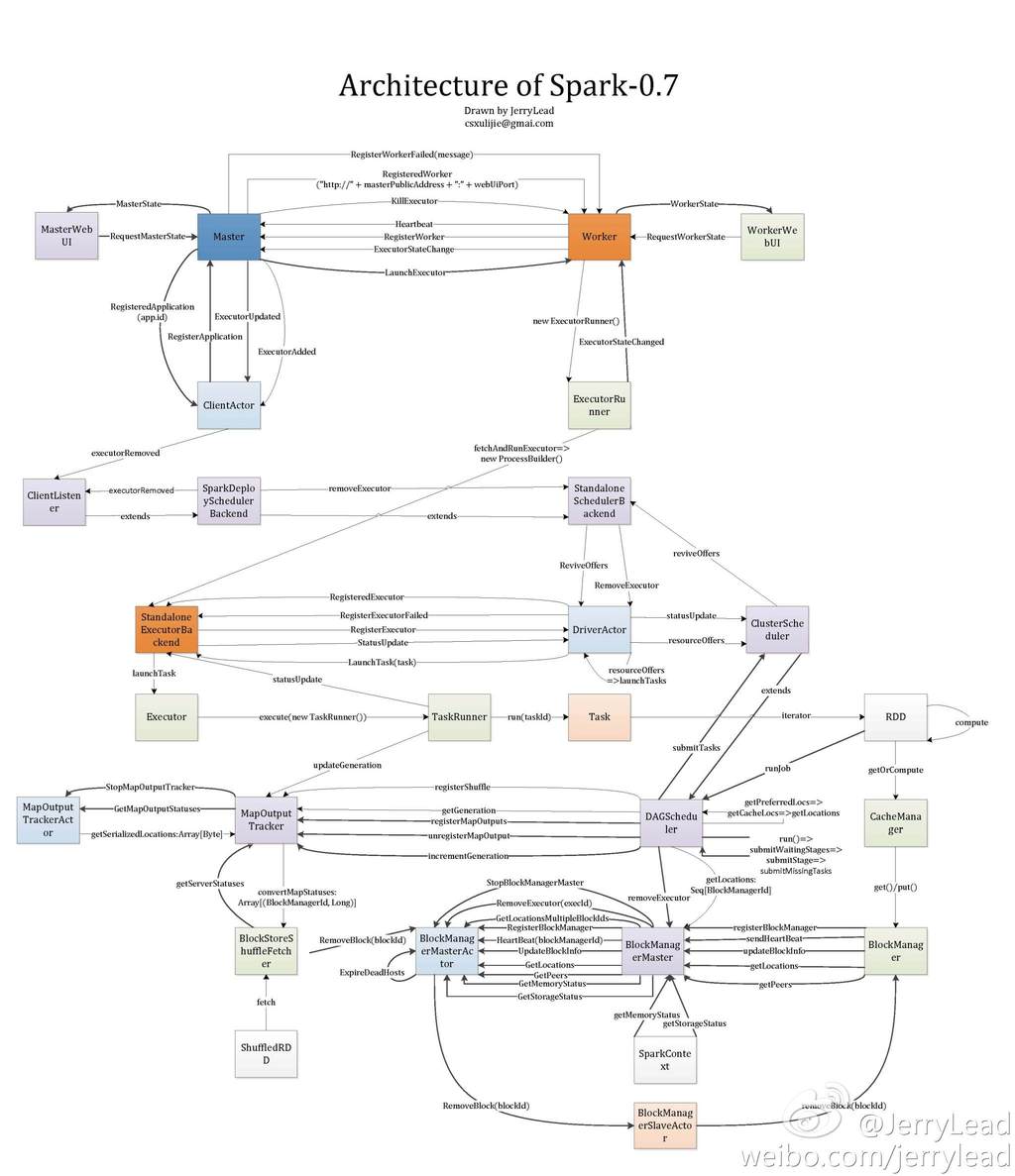
整体上Spark分为以下几个主要的子模块:
deploy:deply模块包括Master,Work和Client,参见architecture图的最上 部分。deploy主要负责启动和调度用户实现的Spark application并且分配资源给用户 application,类似于Hadoop YARN框架。scheduler:scheduler主要负责调度用户application内的tasks,根据部署方式的不 同Spark实现了多种不同的scheduler,包括LocalScheduler,ClusterScheduler等 。rdd:rdd类似于一个分布式的数据集,用户可以根据rdd所提供的api进行数据集的 操作,rdd模块是用户交互的主要模块。storage:storage模块主要负责数据集,也就是rdd的存取。根据设定的不同,数 据可以保存在内存、磁盘或是两者。Spark与Hadoop MapReduce最大的不同在于MapReduce 将数据保存在HDFS上,而Spark则由自己的存储系统。
当然还有一些其他的子模块,可以参考上图。
Spark采用了Actor的设计方式,整体架构,包括各子模块的设计上都是采用master-slave模 式,master和slave之间通信的主要协议可以参见上图。
End
以上大致地介绍了Spark的architecture,之后会陆续对各子模块作详细的介绍