Table of contents
Introduction
Apache Celeborn is a unified big data intermediate service dedicated to improving the efficiency and elasticity of different map-reduce engines. It provides an elastic, high-efficient management service for intermediate data, including shuffle data, spilled data, result data, etc. Currently, Celeborn is focusing on shuffle data.
In order to improve the elasticity of Spark on Kubernetes and solve the flexibility and stability issues of External Shuffle Service, eBay introduced Celeborn as a Remote Shuffle Service.
The Celeborn cluster itself consists of two components: Celeborn Master and Celeborn Worker. The Worker is responsible for data read and write and reports worker info to the Master through heartbeat. The Master ensures the consistency of cluster metadata through the RAFT protocol.
For Celeborn Master, we deploy it in a Cloud Native manner. Celeborn Worker is co-located with the NodeManager of existing compute nodes and managed by systemctl. Currently, the largest cluster has nearly 6000 Celeborn Workers.
Due to the large scale of the cluster and the need to patch the OS of the cluster’s Pods every month, meaning the Worker Pods will restart once every month, we need to manage the Celeborn cluster through automation tools to better ensure the stability of the cluster.
Therefore, we have optimized Celeborn’s RESTful API for better integration with automation tools. These improvements will be available in version 0.6.0, along with the celeborn-openapi-client SDK to assist users in interacting with the new RESTful APIs.
Additionally, since Celeborn 0.5.0, you can view the Swagger UI at http://host:port/swagger to better understand the usage of the API.
This article will explain how we use automation tools to manage the Celeborn cluster with the latest RESTful API.
Celeborn Master Management
For Celeborn Master, we deploy it on Kubernetes. There is an agent container in the Master pod that communicates with automation tools before and after the restart, triggering the podPreStart and podPostStart workflows to determine whether the restart can proceed and whether the service is functioning normally after the restart.
Pre-Restart Workflow for Master Pod
Below is the podPreStart workflow diagram. First, it determines whether it is within the SLA window. If yes, it waits.
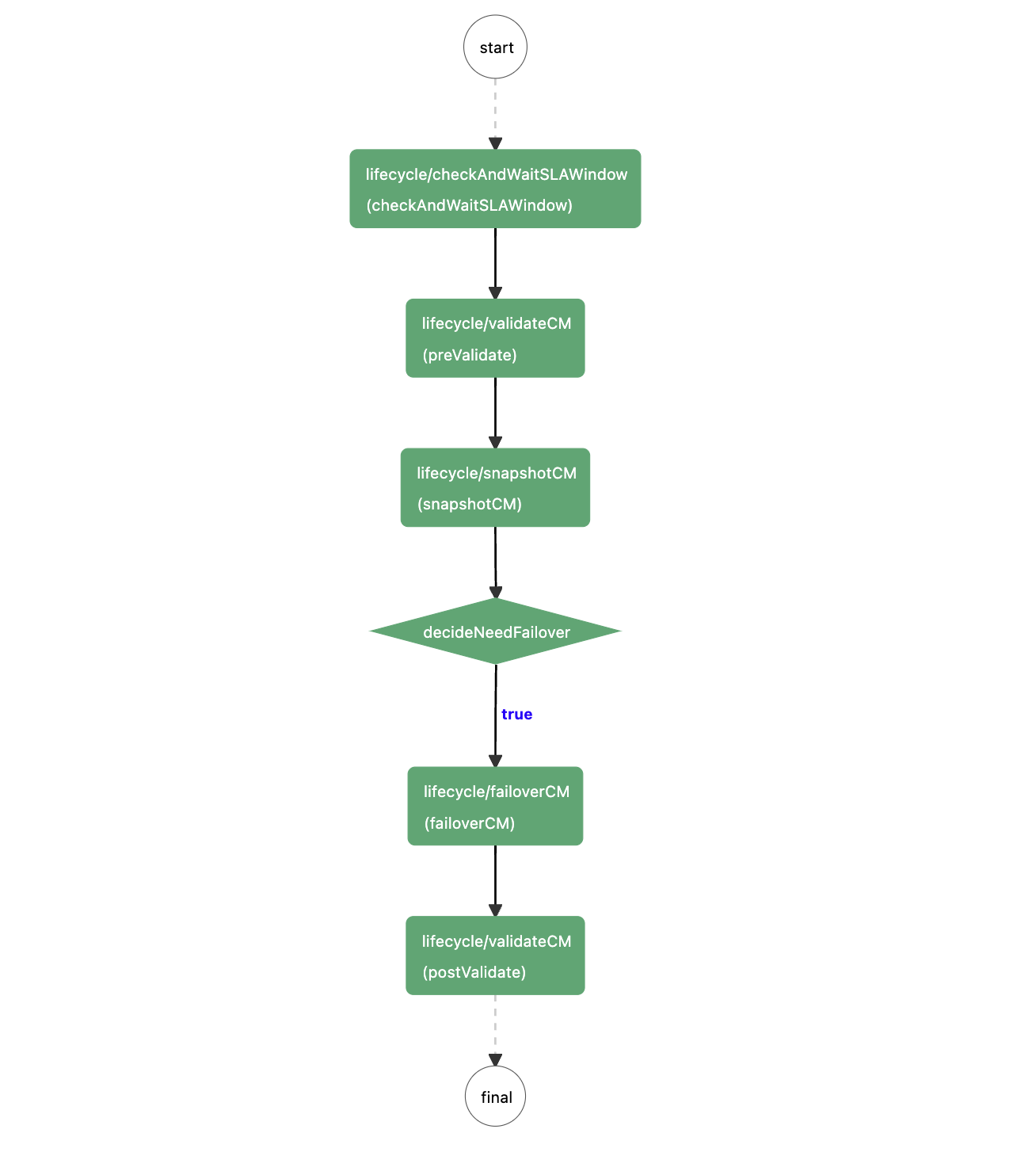
1. Check the Status of the Celeborn Master Cluster
- Since the Master ensures data consistency based on the RAFT protocol, the number of Masters before the restart must be greater than half of the total number plus one. We determine the number of Masters through Prometheus metrics.
- Check that the current cluster has a Master leader by calling the Master API
GET /api/v1/mastersand checking theleaderfield in the response.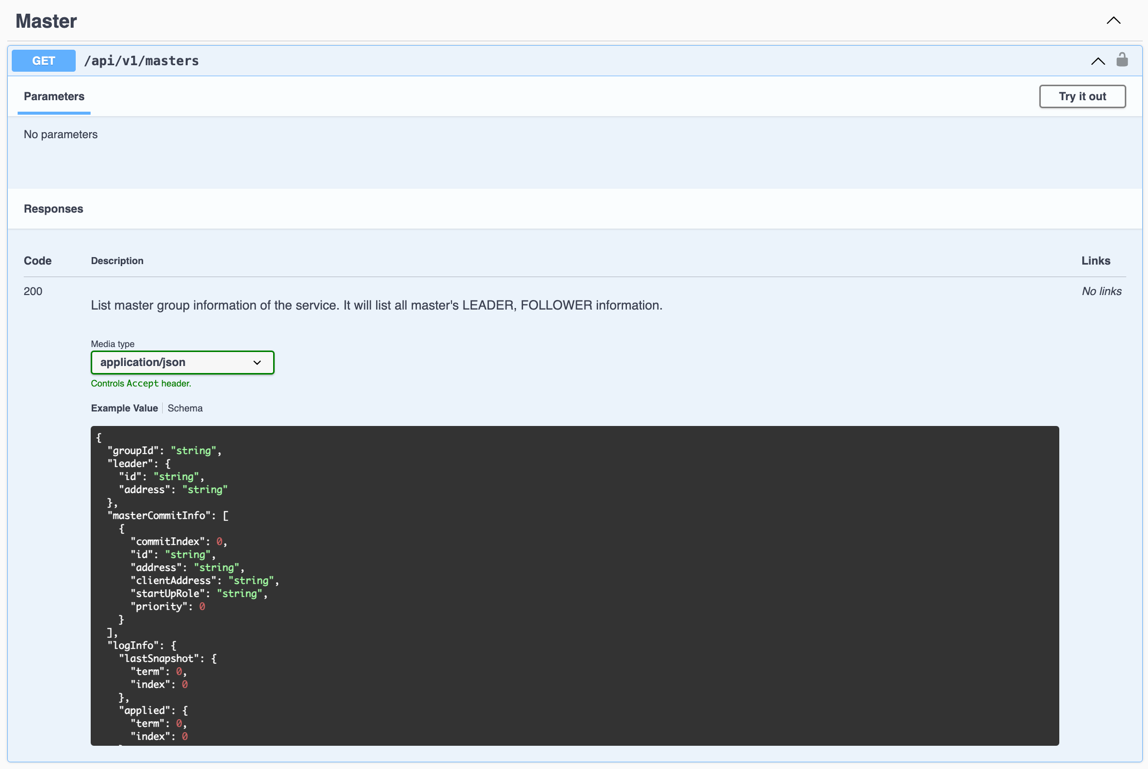
- Confirm that the group size of the current Master cluster is as expected by checking the
masterCommitInfofield’s size in the response. - Check that the commit index of the current active Masters is consistent by checking the
commitIndexfield in themasterCommitInfoof the response. If the gap incommitIndexis greater than a certain threshold, wait.
2. Create Celeborn Master Ratis Snapshot
Ratis is a Java implementation of the Raft protocol. Celeborn uses Ratis to ensure data consistency in the Master cluster. To quickly recover data after a restart, creating a Ratis snapshot before the restart.
Previously, the Celeborn community provided Ratis-shell to manage the Ratis cluster. To better integrate with automation tools, we implemented all Ratis-shell commands as RESTful APIs, facilitating Master failover and Ratis snapshot creation.
Create a snapshot by calling POST /api/v1/ratis/snapshot/create.

3. Perform Celeborn Master Failover and Check as Needed
If the current Master pod is the leader, perform a failover.
- Pause the current pod’s leader election by calling
POST /api/v1/ratis/election/pause.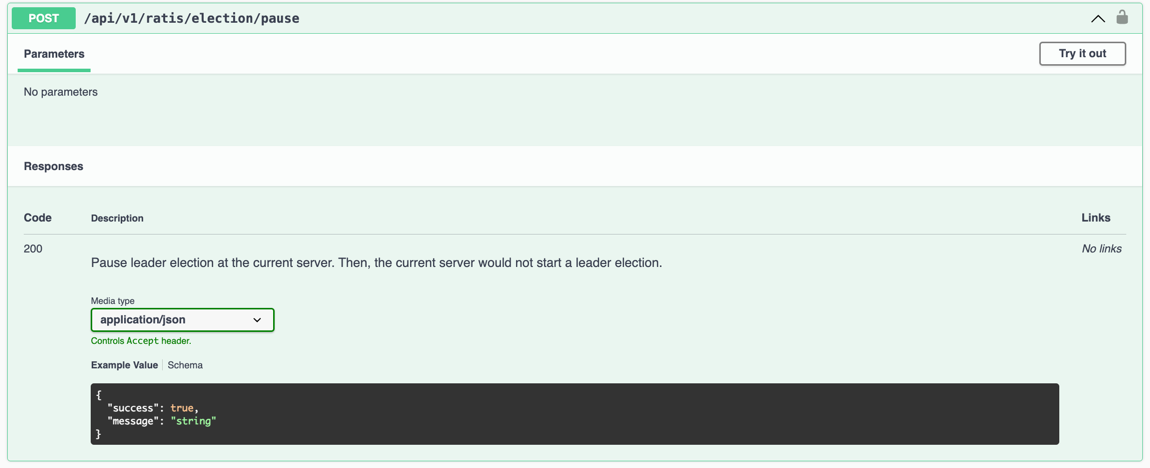
- Step down the current pod’s leader by calling
POST /api/v1/ratis/election/step_down.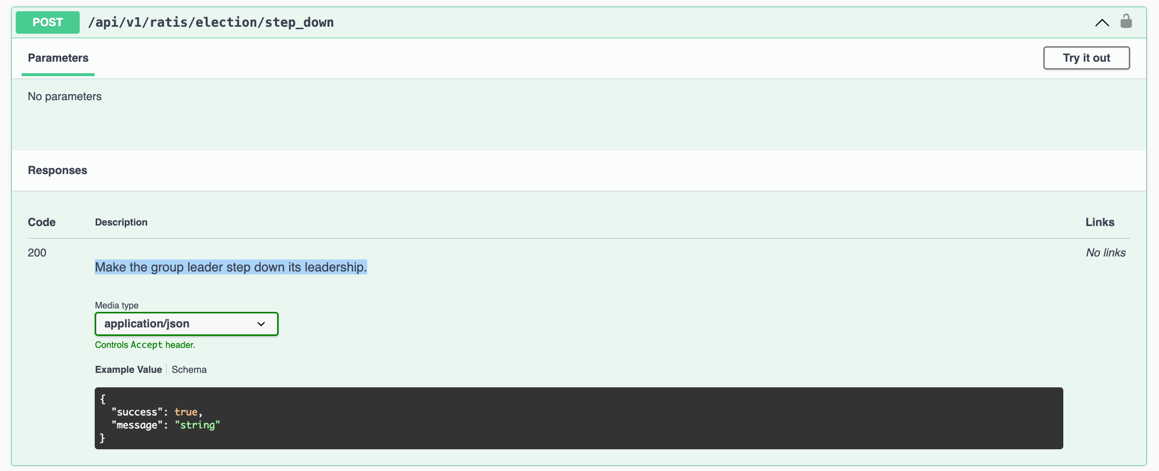
- After waiting for a while, resume the current pod’s leader election by calling
POST /api/v1/ratis/election/resume.
- Recheck the status of the current Master cluster and ensure the leader has changed, meaning the current pod is no longer the leader.
You can also trigger a Master failover separately by calling POST /api/v1/ratis/election/transfer to transfer the leader to a specified Master.
![]()
Post-Restart Workflow for Master Pod
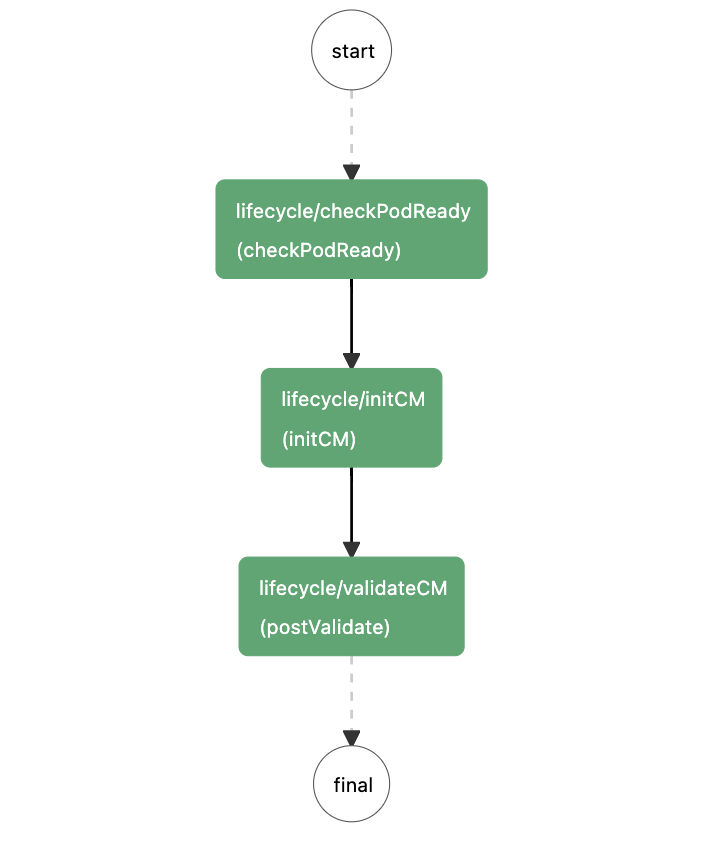
Below is the podPostStart workflow diagram:
- Check if the pod is ready, such as whether the hostname and VIP are normal.
- Perform some initialization operations, such as loading the configuration.
- Check the status of the current Master cluster, which is similar to the pre-restart check. The only difference is that after the restart, it is only necessary to ensure that the number of active Masters is greater than half of the total number.
Celeborn Worker Management
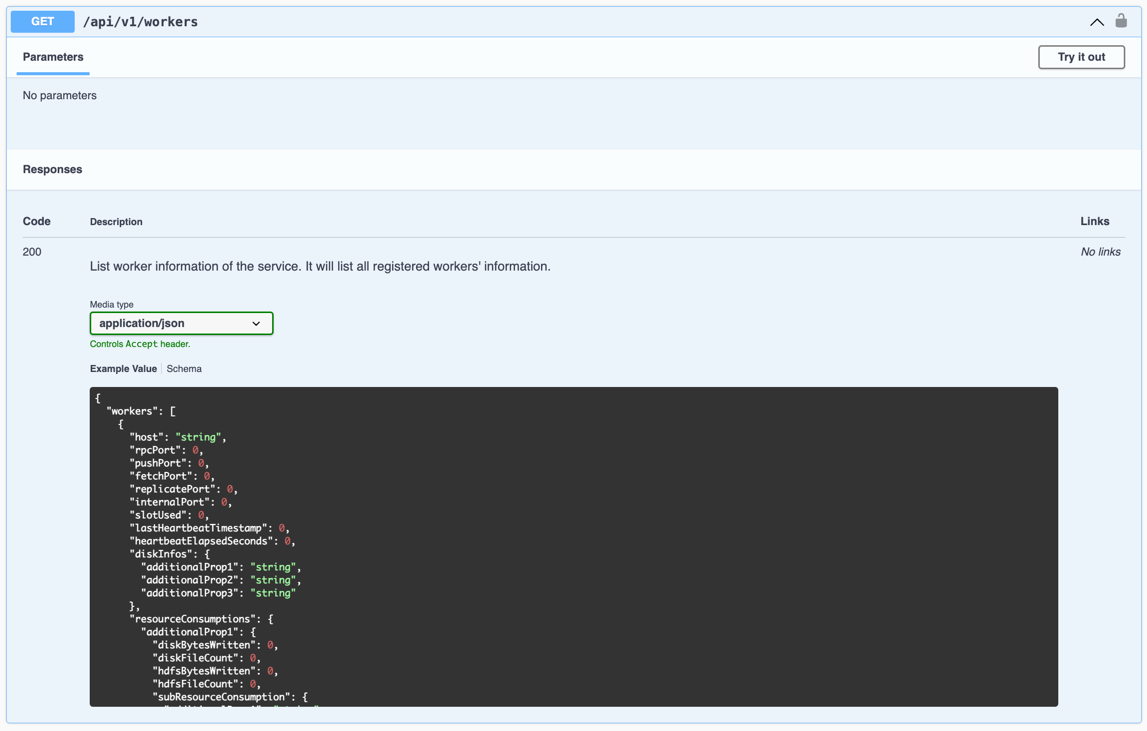
Automation tools periodically call the Master’s GET /api/v1/workers to get the status of all registered Workers, including lostWorkers, excludedWorkers, manualExcludedWorkers, shutdownWorkers, and decommissionWorkers. We also set celeborn.master.workerUnavailableInfo.expireTimeout=-1 so that even if a Worker is offline for a long time, its information will not be cleared (you can call /api/v1/workers/remove_unavailable to clean up as needed).
Worker Decommission
1. Exclude Worker
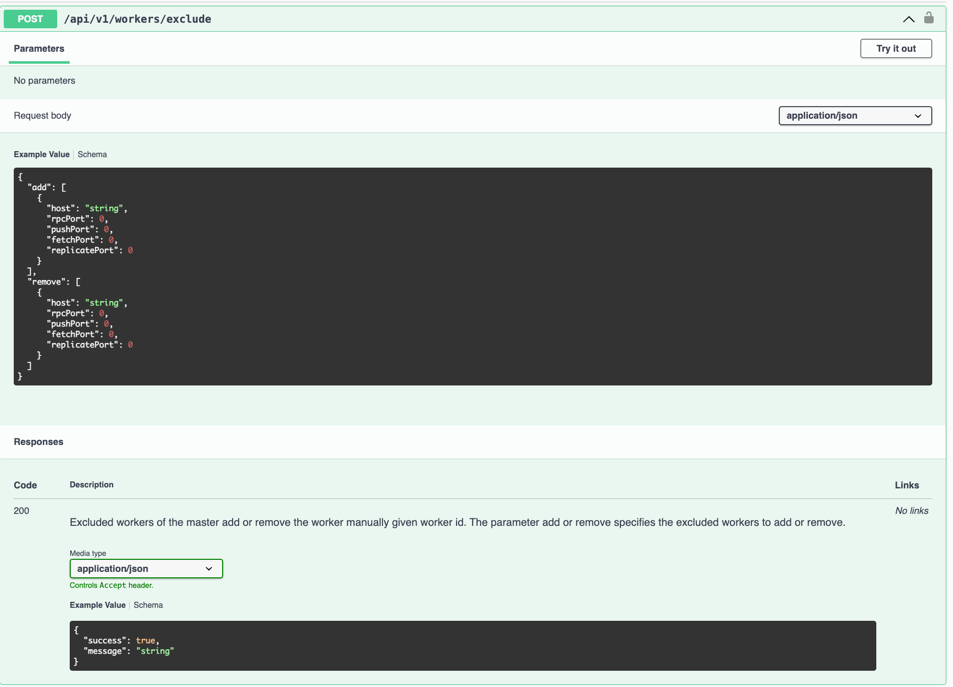
First, call the Master’s POST /api/v1/workers/exclude to add the Worker information to the add field, adding the Worker to the manualExcludedWorkers list so that the Master will no longer assign slots to this Worker.
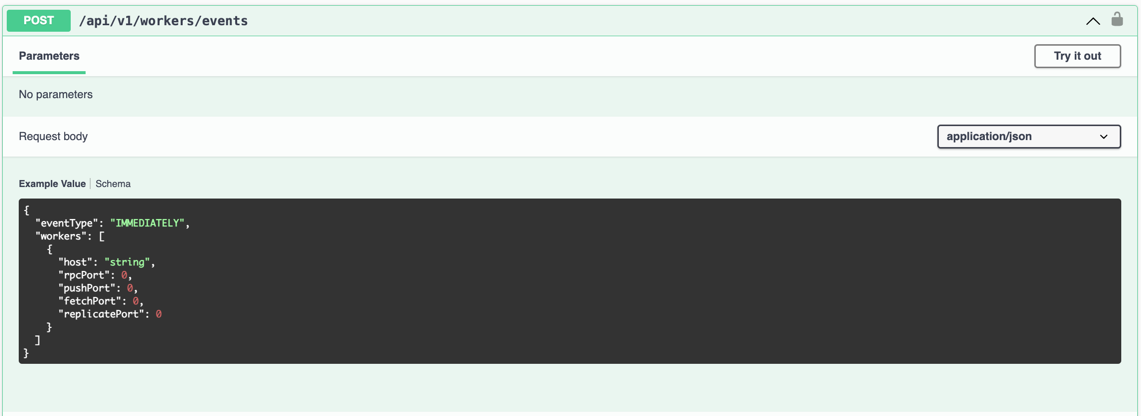
2. Send DecommissionThenIdle Event and Wait for Worker to Enter IDLE State
Currently, Celeborn Master supports event types such as None, Immediately, Decommission, DecommissionThenIdle, Graceful, and Recommission.
For decommissioning, the event types are Decommission and DecommissionThenIdle.
The following diagram shows some Worker states and the transitions between events. The Decommission event will exit the Worker process after completion, while the DecommissionThenIdle event will make the Worker enter the IDLE state after completion.
Since the Worker process will be automatically restarted by systemctl after exiting, we choose to use the DecommissionThenIdle event for decommissioning to better control the Worker’s state.

Call the Master’s POST /api/v1/workers/events with eventType set to DecommissionThenIdle to send the decommission event and wait for the Worker to enter the IDLE state.
3. Graceful Shutdown
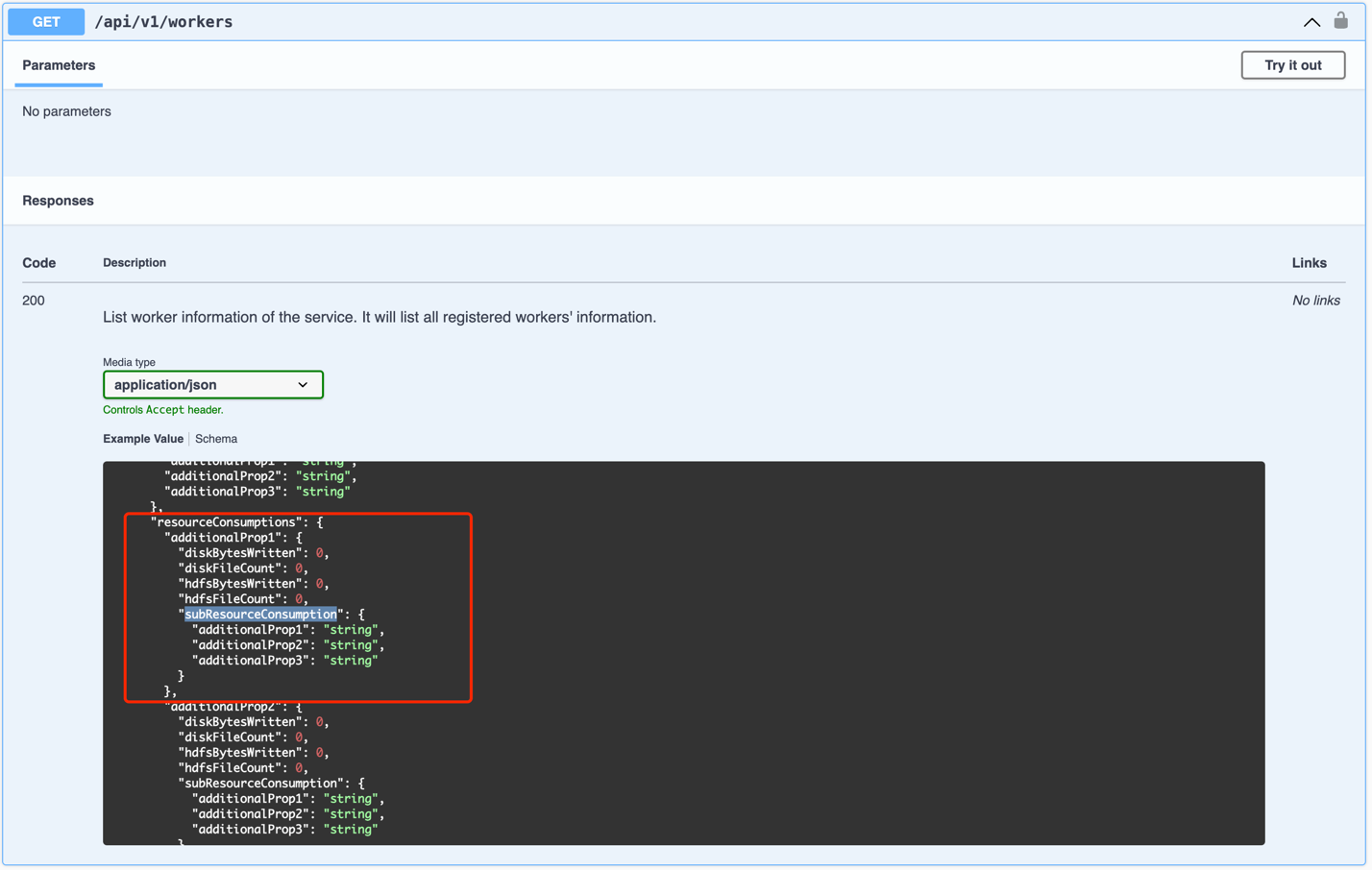
After the Worker enters the IDLE state, check the Worker’s resourceConsumptions.
resourceConsumptions is a map where the key is userIdentifier and the value is the user’s resource usage, including diskBytesWritten, diskFileCount, hdfsBytesWritten, hdfsFileCount, and subResourceConsumptions.
subResourceConsumptions is also a map where the key is applicationId and the value is the application’s resource usage.
We determine whether the Worker has released all shuffle files by checking that there are no non-empty resourceConsumption entries in subResourceConsumptions.
If the Worker has released all shuffle files, it can be gracefully shut down. Otherwise, continue to wait until the waiting time reaches a specified threshold.
Worker Recommission
To re-add a Worker to the cluster, simply call the Master’s POST /api/v1/workers/exclude and put the Worker information in the remove field to remove the Worker from the manualExcludedWorkers list, allowing it to assign slots again.
Summary
This article introduces some practices for automating the management of Celeborn clusters based on the latest RESTful API, with all API calls accessing the Master’s API.