目录
前言
Apache Celeborn 是一个统一的大数据中间服务,致力于提高不同MapReduce引擎的效率和弹性,并为中间数据(包括shuffle数据、溢出数据、结果数据等)提供弹性、高效的管理服务。目前,Celeborn专注于shuffle数据。
为了Spark on Kubernetes的弹性以及解决External Shuffle Service的灵活性和稳定性不足,eBay引入 Celeborn 作为Remote Shuffle Service。
Celeborn 集群本身分为两个组件,Celeborn Master 和 Celeborn Worker, Worker负责处理数据的读写,并通过心跳将各种信息汇报给 Master, 然后Master通过raft 协议保证集群数据的一致性。
对于Celeborn Master,我们进行Cloud Native部署, Celeborn Worker与现有的计算节点的NodeManager进行混布,使用systemctl管理Worker服务进程, 目前最大的集群大概有接近6000台 Celeborn Worker。
由于集群规模较大,而且每个月都需要对集群的Pod进行OS patching,也就是说每个月Worker Pod都会重启一次,所以我们需要通过自动化工具来管理Celeborn集群,以便更好地保证集群的稳定性。
因此,我们对 Celeborn 的RESTful API 进行了优化,以便更好地与自动化工具进行集成。这些改进将在 0.6.0 版本中发布,并且 celeborn-openapi-client SDK 也将可用,以帮助用户与新的 RESTful API 进行交互。
另外在 Celeborn 0.5.0 之后就支持通过 http://host:port/swagger 来查看swagger UI, 可以更好地了解API的使用。
本文将介绍我们如何基于最新的RESTful API集成自动化工具来管理Celeborn集群,其他方面不再详细说明。
Celeborn Master 管理
对于Celeborn Master我们是部署在Kubernetes,在Master pod 里有一个 agent 的container,会在重启前和重启后和自动化工具进行通信,触发 podPreStart 和 podPostStart workflow,来判断是否能够重启以及重启后服务是否正常。
Master Pod重启前流程
下面是 podPreStart workflow 的流程图,首先判断当前是否处于 SLA window,如果是则等待。
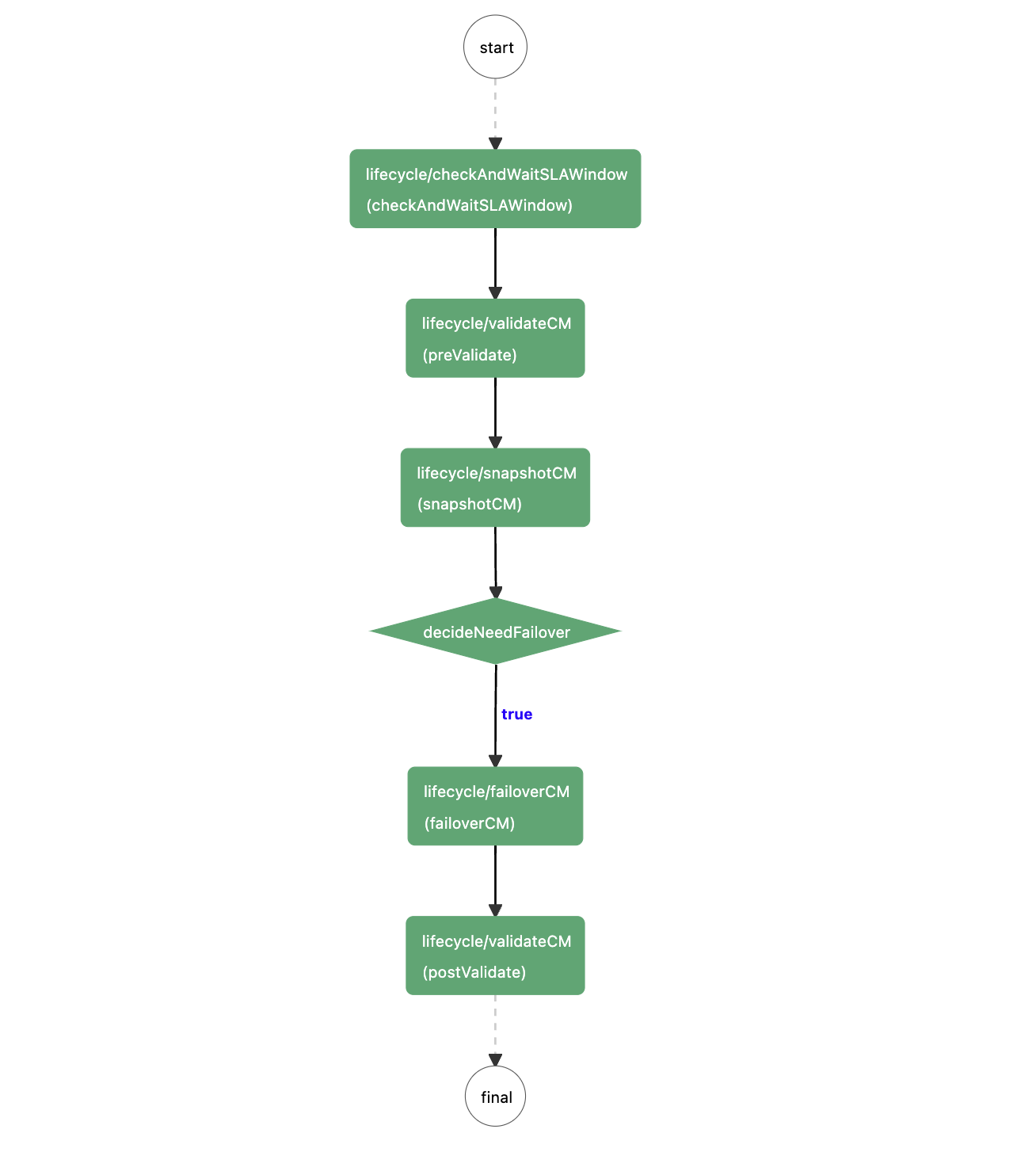
1. 检查 Celeborn Master 集群的状态
- 因为Master基于RAFT协议保证数据的一致性,所以重启前Master 的数量要大于总数量的一半 + 1,Master 数量目前是通过Prometheus的Metrics来判断。
- 检查当前集群Master集群拥有Leader,通过call Master API
GET /api/v1/masters, 然后检查返回结果leader字段.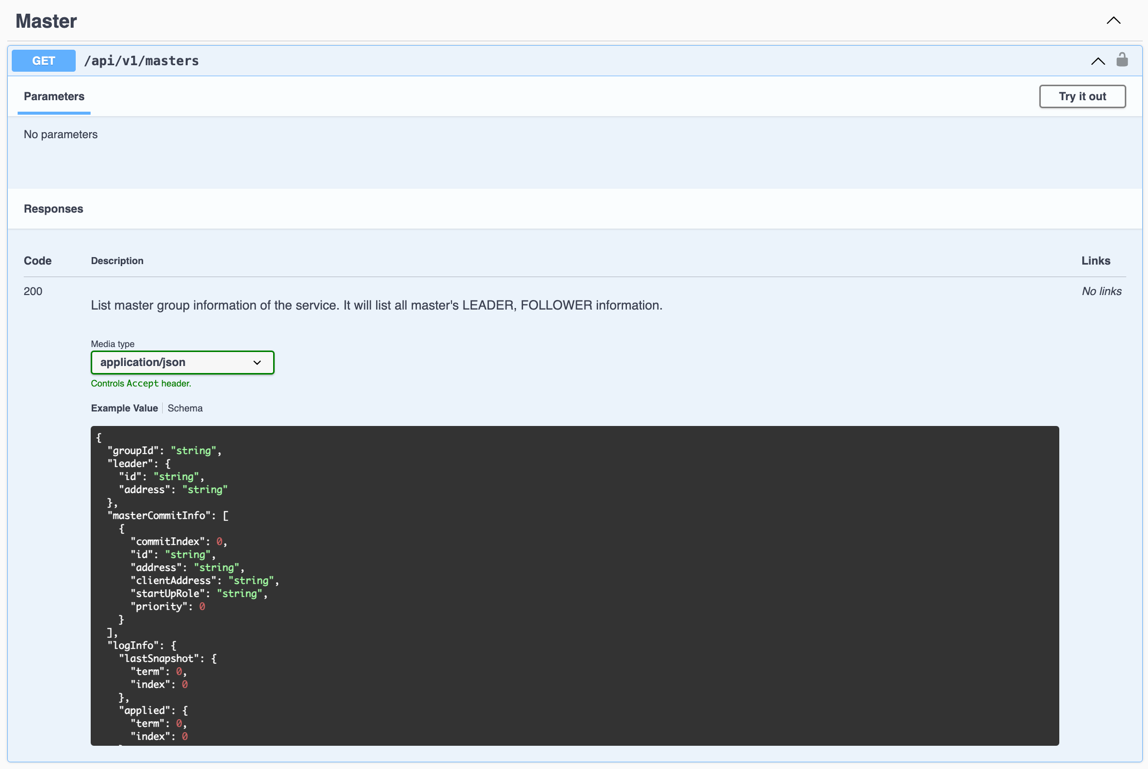
- 确认当前Master 集群的group size是预期的,检查返回结果的
masterCommitInfo字段的size. - 检查当前活着的Master的 commit index 是否一致,检查返回结果的
masterCommitInfo的commitIndex字段, 如果commitIndex的gap大于一定的阈值,则需要等待。
2. 创建 Celeborn Master Ratis 快照
Ratis是一个Raft 协议的Java实现,Celeborn 使用Ratis来保证Master集群的数据一致性,为了在重启后快速恢复数据,会在重启前创建Ratis的快照。
Celeborn社区之前提供了Ratis-shell来管理ratis 集群,为了更好地和自动化工具进行集成,我们把所有ratis-shell命令都进行了RESTful实现, 方便进行Master的Failover以及创建Ratis快照。
通过调用 POST /api/v1/ratis/snapshot/create 来创建快照。

3. 按需进行Celeborn Mastere Failover以及检查
如果当前Master Pod是Leader, 则需要进行Failover。
- 暂停当前Pod的Leader选举,调用
POST /api/v1/ratis/election/pause。
- 让出当前Pod的Leader, 调用
POST /api/v1/ratis/election/step_down。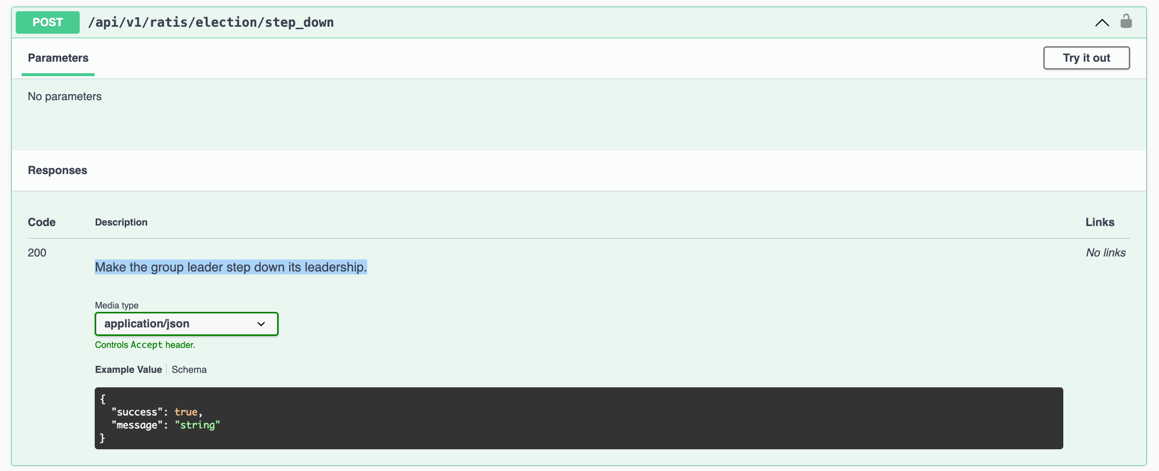
- 等待一段时间之后,恢复当前Pod的Leader选举,调用
POST /api/v1/ratis/election/resume。
- 重新检查当前Master集群的状态,并确保Leader已经变更,即当前Pod不再是Leader。
另外也可以单独触发 Master Failover, 调用 POST /api/v1/ratis/election/transfer 将leader转移到指定的Master上。
![]()
Master Pod重启后流程
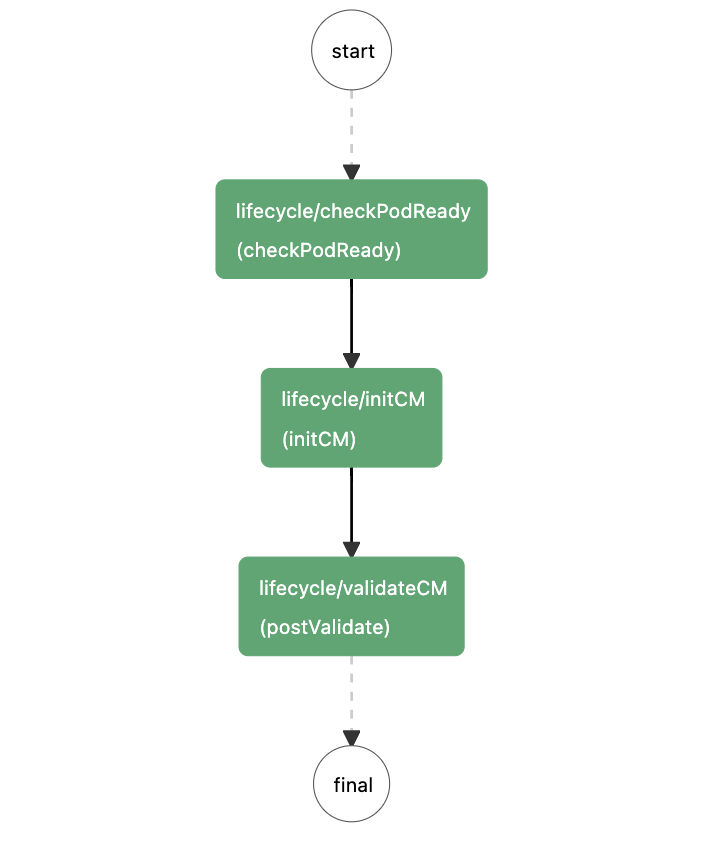
下面是 podPostStart workflow 的流程图:
- 检查pod 是否ready,比如 hostname 和 VIP 是否正常。
- 进行一些初始化操作,比如load conf。
- 检查当前Master集群的状态,跟Pod重启前的检查基本一样,唯一不同的是,重启后只需确保活着的Master数量大于总数量的一半即可。
Celeborn Worker 管理
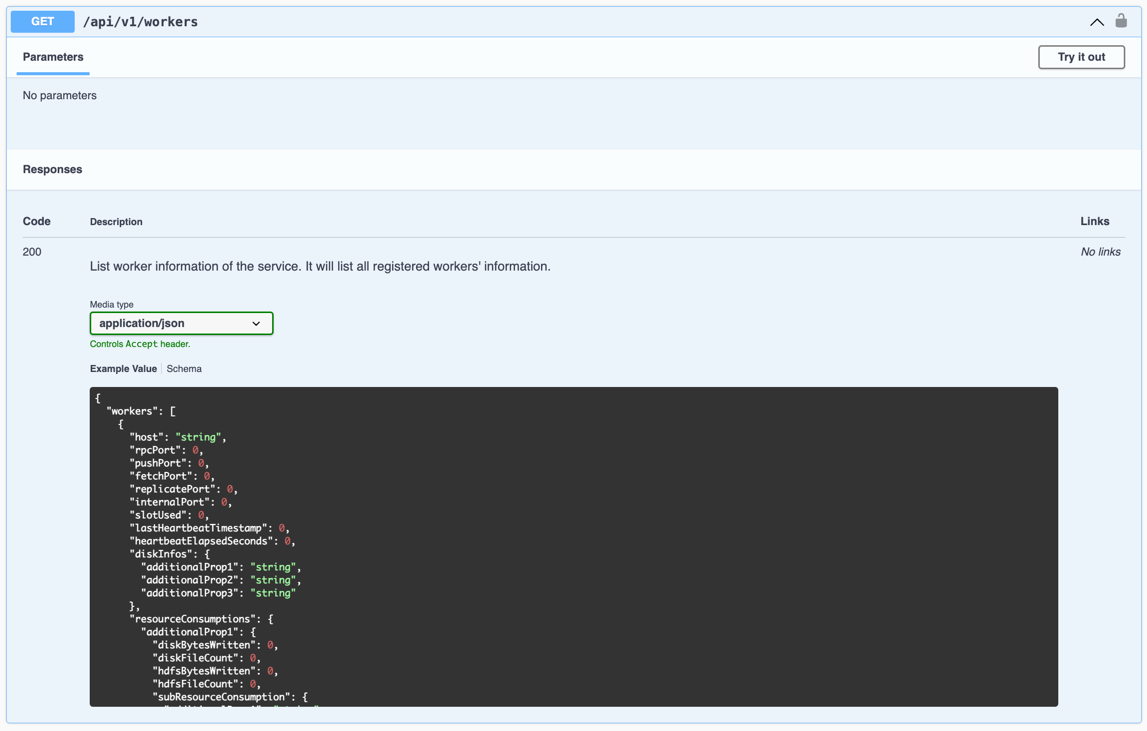
自动化工具会周期性调用 Master的 GET /api/v1/workers 来获取所有的注册的Worker的状态,包括 lostWorkers, excludedWorkers, manualExcludedWorkers, shutdownWorkers 和 decommissionWorkers。
同时我们设置了 celeborn.master.workerUnavailableInfo.expireTimeout=-1, 以便即使Worker长时间下线,其信息也不会被清除掉(可调用 /api/v1/workers/remove_unavailable 按需清理)。
Worker decommission
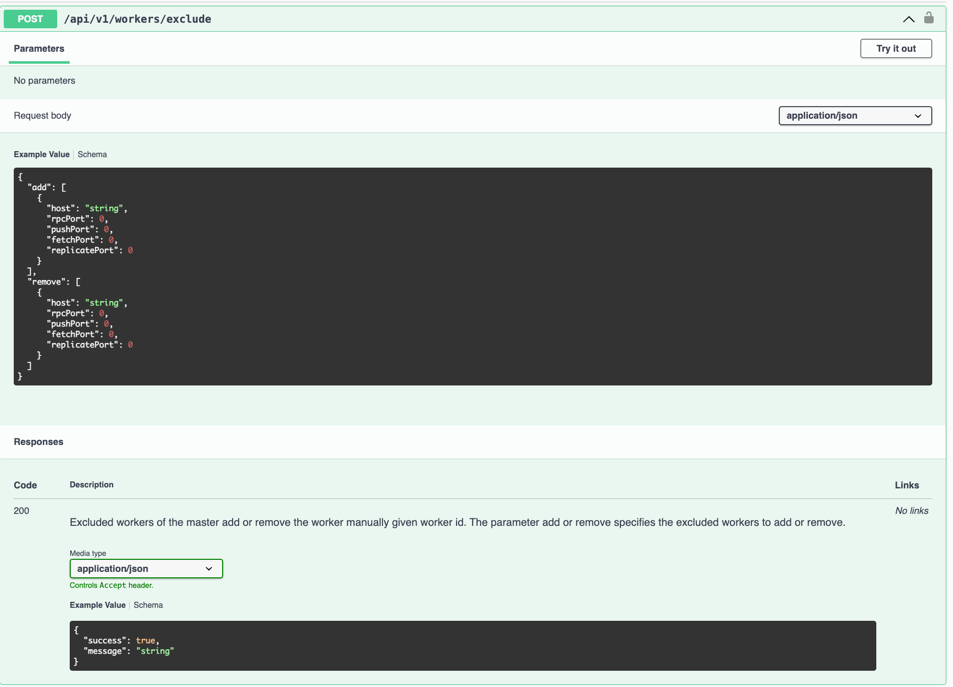
1. Exclude Worker
首先,调用 Master POST /api/v1/workers/exclude 把worker信息放入 add 字段把worker加入到 manualExcludedWorkers 列表中,这样Master就不会再往这个worker上分配slots。
2. 发送 DecommissionThenIdle event 并等待Worker进入IDLE 状态
目前Celeborn Master支持的events类型有 None, Immediately, Decommission, DecommissionThenIdle, Graceful, Recommission.
用于 Decommission 的event类型有 Decommission 和 DecommissionThenIdle.
下图是一些Worker State和event之间的转换图,其中 Decommission event会在完成之后,退出Worker 进程,而 DecommissionThenIdle event 是在完成之后,让Worker进入IDLE状态。
由于Worker进程在退出之后会被systemctl 自动拉起,所以我们选择使用 DecommissionThenIdle event来进行Decommission操作,以便更好地控制Worker的状态。

调用 Master POST /api/v1/workers/events, eventType 为 DecommissionThenIdle 来发送Decommission事件, 并等待Worker进入IDLE状态。
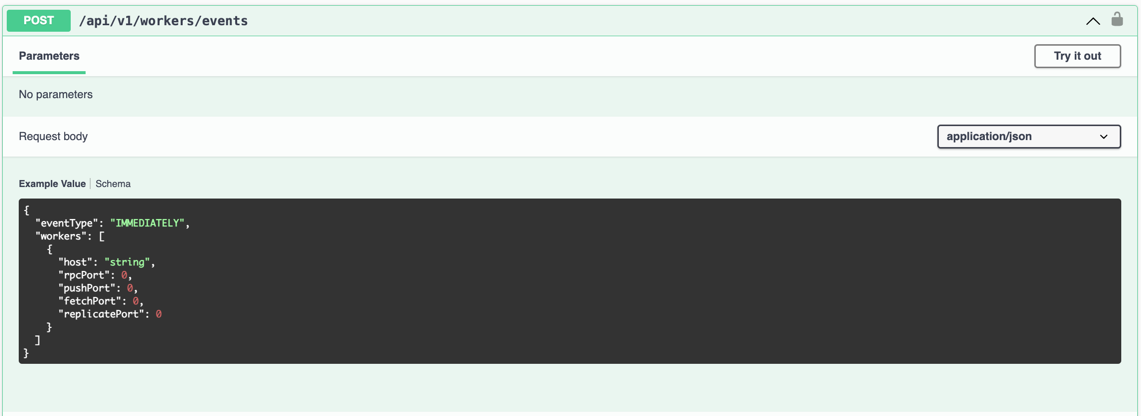
3. Graceful Shutdown
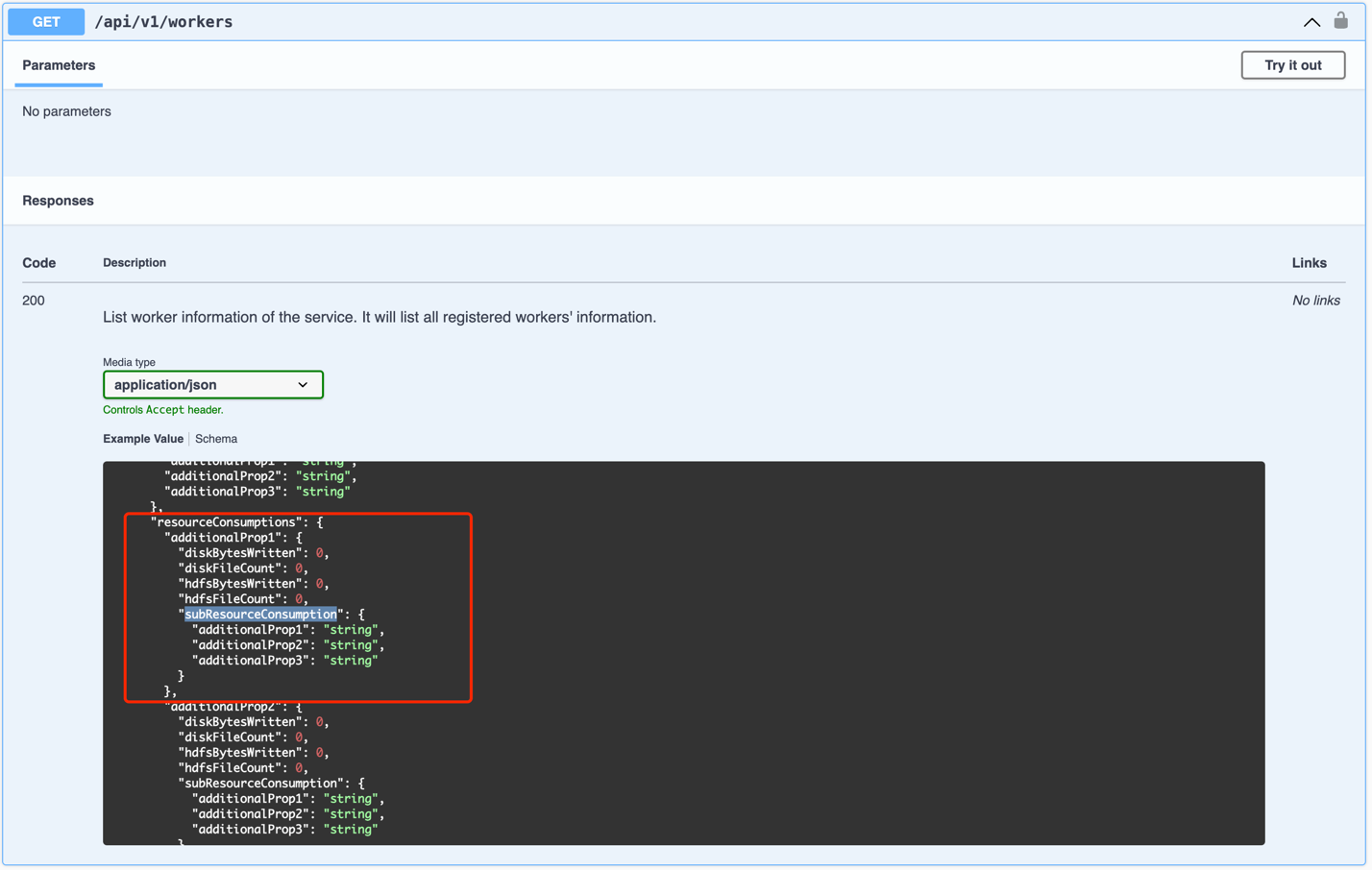
在 Worker 进入IDLE 状态之后,检查Worker的 resourceConsumptions.
resourceConsumptions 是 一个map,key 为 userIdentifier, value用户的资源占用情况,包括 diskBytesWritten, diskFileCount, hdfsBytesWritten, hdfsFileCount 和 subResourceConsumptions。
subResourceConsumptions 也是一个map,key 为 applicationId, value是 application的资源占用情况。
通过判断当前Worker 上面不存在 subResourceConsumptions 非空的 resourceConsumption 来判断当前worker是否已经释放所有shuffle文件。
如果Worker已经释放所有shuffle文件,那么就可以graceful的shutdown当前Worker,否则需要继续等待,直到等待时间到达一个指定的阈值。
Worker recommission
当要把一台worker 重新加入到集群中时,只需调用 Master POST /api/v1/workers/exclude 把 worker信息放入 remove 字段即可将worker 从 manualExcludedWorkers 中移除, 重新接受分配slots。
总结
本文介绍了eBay基于最新RESTful API 进行自动化管理Celeborn集群的一些实践,所有API调用都是访问Master的API。