目录
前言
本文讲eBay Spark测试框架-Woody, 其已被发表在公众号eBay技术荟Hadoop 平台进阶之路|eBay Spark测试框架–Woody
新版本的Spark拥有更好的性能和稳定性,对于用户来说,如果长期停留在低版本的Spark,不仅会浪费集群资源,还会进一步加大平台管理团队的工作量。如果进行Spark大版本升级,考虑到版本间可能由于计算行为不一致而导致的数据质量问题,用户就要投入大量的精力去对比重要的job在不同版本下的数据质量,加大了版本升级的困难度。
ADI Hadoop team负责管理eBay的Hadoop集群、 Spark的版本升级和bug修复等事务。为了提升Spark版本升级的效率,本团队开发了Spark测试框架——Woody。该测试框架会将线上spark-sql job语句转换为和线上job隔离的测试语句,然后调用不同的Spark版本执行测试语句,最终对比版本间数据质量。Woody不仅可以用于Spark版本升级,也可用于job调优以及job pipeline的端到端测试。本文将分享Spark测试框架Woody的架构,实现以及使用场景,希望能对读者有所帮助。
背景
Hadoop team目前管理两个大Spark分支,Spark-2.1和Spark-2.3,目前的版本开发均基于Spark-2.3,而对于Spark-2.1分支已经不再进行维护,未来会升级到Spark-3.0。
Hadoop team从两年前就着手进行从Spark-2.1 到Spark-2.3的迁移工作,用了将近两年时间完成了迁移。
为什么会用这么长时间呢?
因为大版本之间可能会存在不兼容问题,计算行为可能发生改变,也就是说两个版本间的计算结果可能不一致。
数据质量是至关重要的,特别是对于金融数据,业务团队需要在升级之前进行两个版本间的计算结果对比。
而这需要用户去手动修改线上代码,然后利用两个Spark版本进行双跑,最后再去手动对比两个版本的计算结果。eBay内部的spark-sql任务数不胜数,大版本升级会消耗大量的资源和人力。
Spark-2.1到Spark-2.3 已经耗费了这么长时间,那么将来升级到Spark-3.0想必也是一个浩大的工程。
为了解决这个问题,Hadoop team开发了一个Spark测试框架,命名为Woody。Woody的名字取自一个卡通啄木鸟,希望可以帮助找出不同Spark版本之间或者Spark job中的bug(虫子)。
Woody可以将线上的SQL语句进行转换,然后分别启动两个Spark版本运行转换后的SQL,从而对比两个版本的计算结果,判断两个版本计算结果是否一致,也可以用于比较两个版本的性能。
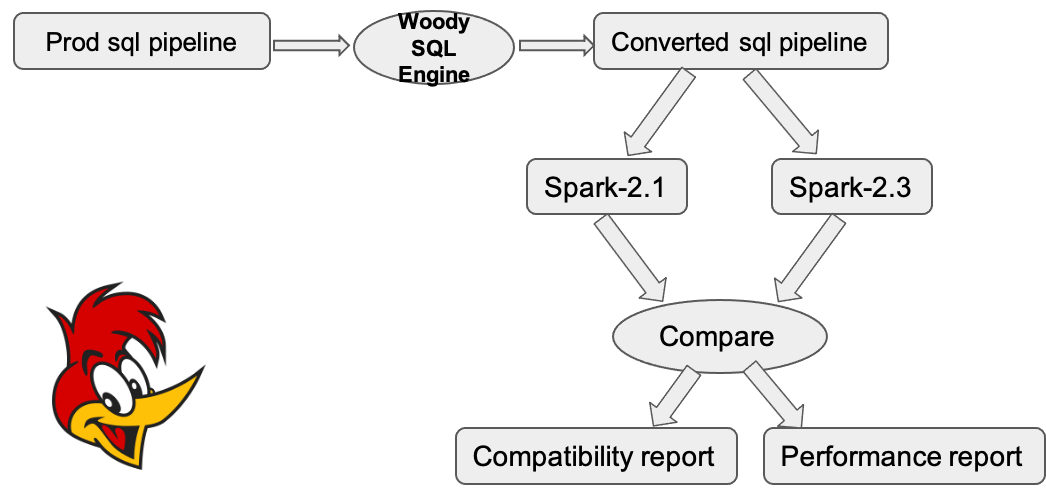
Woody的架构
Woody的架构如图2所示,提供restful api,使用mysql存储数据,支持多个集群。用户可以一次提交一批用于测试的job,Woody用一个workflow封装这批job,由workflow调度器进行调度,每个workflow调度时生成一个对应的jobSetManager,进入job调度器,job调度器会限制同时运行job的数量。
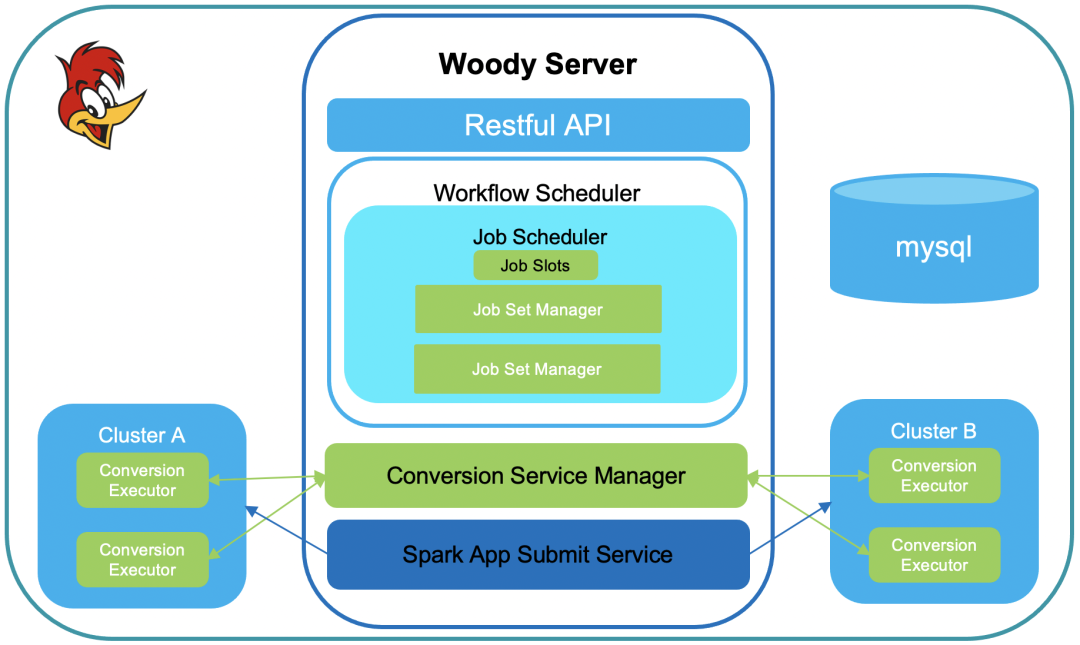
一个job的生命周期为:
- 将job语句转换为测试语句
- 测试运行前准备工作
- 调用Spark版本1运行测试语句
- 计算Spark版本1结果的校验信息
- 调用Spark版本2运行测试语句
- 计算Spark版本2结果的校验信息
- 给出数据质量报告
关于job语句的转换,Woody为各个集群启动多个长运行的conversion executor,这些conversion executor会向Woody Server进行注册并定期汇报自己的心跳,由Conversion Service Manager来管理。
在job需要运行测试语句阶段,Spark App Submit Service会向相应的集群提交Spark任务, Woody会记录其ApplicationId存入mysql。
Woody使用mysql共享状态数据,支持HA, 是cloud-native的服务。在一台Woody服务关闭时会将其正在运行的workflow标记为游离状态,这些游离状态的workflow会被其他正在运行的Woody服务接管,或者由当前Woody服务重启后重新接管。
Spark-sql Job
首先,介绍一下本文中对source表,working表和target表的定义:
- source表是作为输入的表,是被select from的表;
- working表是在job运行中被创建的表,包括(temporary)view;
- target表是被写入数据的表,比如被load数据,或者被insert数据等等。
前面提到了用户在测试版本间数据质量的时候,需要手动对两个Spark版本间的计算进行对比,这一操作有以下三个要点:
- 更改SQL语句,至少需要更改insert数据的表名,避免影响线上job;
- 保持source表的数据一致;
- 手动检查两个Spark版本的计算结果。
Woody需要自动化完成以上三方面的工作。
首先,对于如何去自动地更改线上job语句,请参考以下这组简单的Spark-sql语句:
create or replace temporary view working_table as select c1, c2, …, cn from src_table;
insert overwrite target_table select working_table.c1 from working_table;
在这组语句里面,由src_table 作为job的输入,而working_table是在job运行时候生成的,target_table则作为job的输出。
如果要更改线上job语句,不被改变的src_table是不用更改的,作为输出的target_table是必须修改的,临时(temporary)的working表(temporary view)是不用更改的,非临时的working表则必须更改。
那么如何才能找出这些src, working和target表呢?
Logical Plan
Catalyst是Spark-sql可扩展的SQL优化器。它会将一条SQL语句或者dataframe操作转换为logical plan,然后进行优化,最后转换成可执行的物理计划运行,因篇幅限制,此处不做过多展开。
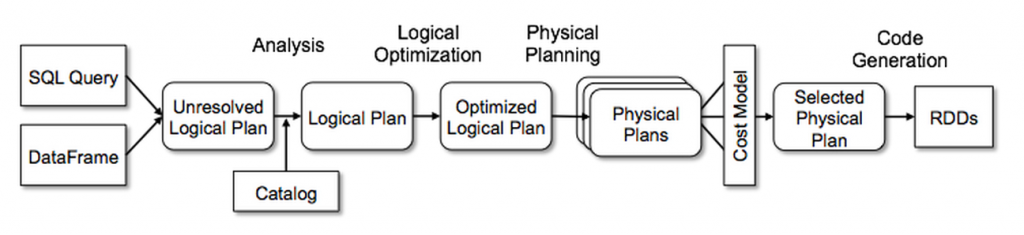
如上图所示,Woody会使用其中的unresolved logical plan 来进行分析,来找出其中的source表,working表,target表和一些location等信息。
比如,下面的这句SQL会转换为一个logical plan,可以从叶子节点拿到该语句的source表信息;而对于create table语句,它对应一个CreateTable类型的logical plan,可以从该plan拿到working表信息;相应的insert语句对应于一个InsertIntoTable类型的logical plan,可以从中获得target表等等。
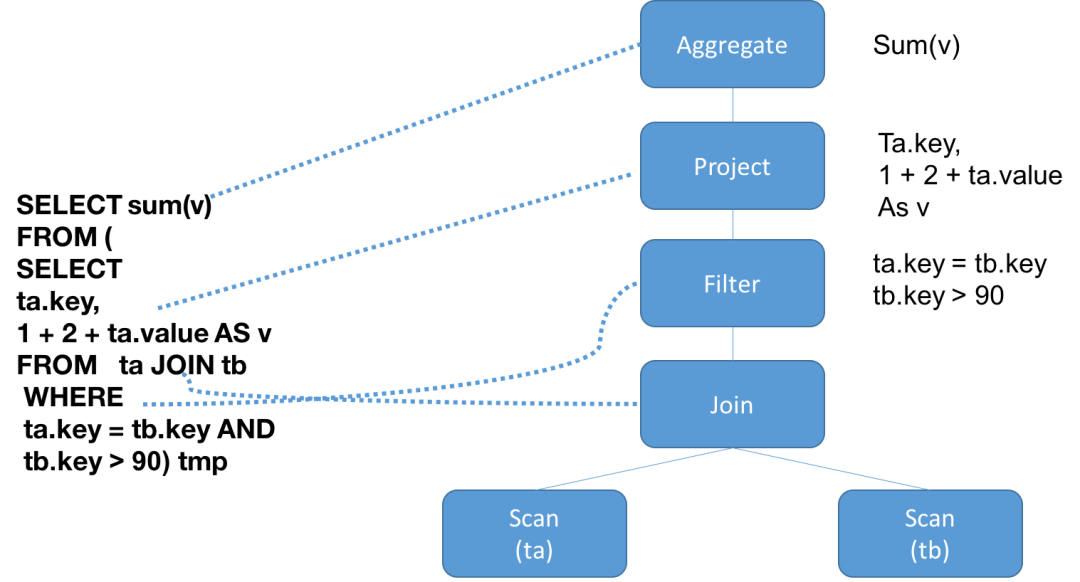
前文提到可以从一个LogicalPlan的叶子节点拿到其中的source表信息。每个logical plan对应一个抽象语法树,而这颗抽象语法树上面的每个节点也是一个logical plan,所以一条语句的logical plan对应的其实是一个森林,Woody要找到的就是这个森林里面的所有叶子节点。
比如说下面的语句:
SELECT c1, udf(c2) from (SELECT current_timestamp as c1, (SELECT count(1) from ta) as c2) tb;
其中subQuery的Project列表里面的第二列,包含source表信息,Woody需要将这个logical plan对应的森林各个分支都进行遍历,找到所有叶子节点,从中提取出表信息。
当然在一个sql job中是有很多条sql语句的,上一条语句的target表可能是下条语句的source表,前面创建的working表,可能是后面用到的source表,以及语句中会有AlterTableSetLocation等等语句,Woody会把解析过程中的context保存起来,用于串联前后表之间的依赖关系,从而进行语句转换。
不只是表信息,对于location的信息,Woody也要进行提取,用于后面转为测试环境中的location等等。
ParserRuleContext
即使找到了语句中的表信息和location信息,那又要如何利用这些信息对原有的sql语句进行转换呢?单纯的利用logical plan是无法做到的,即使编辑了这个logical plan也无法将其映射为sql文本。
Spark使用antlr4 进行语法分析,每个sql文本初次转换之后会获得一个ParserRuleContext,然后catalyst会基于它生成相应的logical plan。
而ParserRuleContext包含一个inputStream对应原始的SQL文本,而且ParserRuleContext也是一颗树,其各个节点也都有自己的类型,每个节点有字段代表其在该inputStream上面的偏移量。
比如说表名对应TableIdentifierContext,location 对应LocationSpecContext。如果要替换一些表名或者location,只需要找到这些表名所在的ParserRuleContext节点,然后将其对应的文本进行替换,再和前后的文本进行拼接,即可对语句进行转换。
举个例子:
SELECT * FROM ta a JOIN tb b ON a.id=b.id;
对于这个语句,如果我们要转换它的source表ta和tb,就要先拿到对应的ParserRuleContext,找到表名节点,得到其在ParserRuleContext inputStream之上的偏移量;假设ta对应的TableIdentifierContext偏移量是50-52,而tb对应的偏移量是70-72。
那么替换的结果就是:
originText(0, 49) + replace(ta) + originText(52, 69) + replace(tb) + originText(72, length).
接下来讲Woody的转换规则。
语句转换
隔离
首先,转换后的语句必定要与线上环境隔离开来,不能影响线上job和数据。Woody的策略是创建一个数据库专门用于对这个job的测试,然后将该job中要输出的数据全部保存在该数据库下面。
假设这个数据库命名为 WOODY_DB_${UNIQUE_ID}。
对于job中只读的source表,Woody不会去转换这些表的名字。对于job中的输出表,其原有的名字是dbName.tblName, Woody会将其表名转换为WOODY_DB_${UNIQUE_ID}.dbName__tblName,也就是说把数据输出到前面提及到的数据库中,原有的数据库名和表名用两条下划线拼接作为新的表名。
举个例子:
insert into gdw_tables.tgt_tbl select * from gdw_tables.src_tbl;
会被转换为
insert into WOODY_DB_{UNIQUE_ID}.gdw_tables__tgt_tbl select * from gdw_tables.src_tbl;
Context
Woody保存转换过程中提取到的信息以及当前的上下文,包含有:
- source表以及这些表是否是global的表;
- 后续当做target表的source表;
- 语句中创建的working表;
- 被后续当做source表的working表;
- 被后续当做target表的working表;
- target表以及其被写入的partition信息;
- 在job中被写入数据的dir信息;
- 当前的数据库是什么,use database语句可更改当前数据库;
- 当前被alter(包括被写入数据,alter location等等)的表的信息等。
接下来介绍Woody如何提取信息,并将这些信息存入该context,串联整个job。
提取
Woody会按照job语句顺序,提取当前语句中的信息,存入context中,然后转换当前语句,如此循环。
对于一条语句,首先得到对应的unresolved logical plan。
此处解释下为什么一定是unresolved logical plan, 不能是resolved logical plan或者optimized logical plan。
因为这是发生在Woody提取信息过程中,并没有真正地运行sql,前置的sql都没有运行,而当前语句可能依赖前置sql的结果,比如依赖前面创建的temporary view,自然无法resolve logical plan 和后续的optimized logical plan(而且optimized logical plan经过catalyst优化,可能会丢失一些需要用于转换原语句的信息)。
拿到unresolved logical plan之后,Woody会去匹配该plan的类型,看其是DDL,DML还是DQL,首先保存不属于source表的信息(working表,target表, 需转换的location信息)。
- CreateViewCommand/CreateViewUsing/CreateTable等创建表语句,将被创建的working表信息存入context,同时记录指定的location信息;
- LoadDataCommand和insert语句,将被insert数据的表以及partition信息存入context;
- AlterTable语句,将alter信息加入context…
之后,Woody会遍历该logical plan的每一个分支(logical plan的children方法不能覆盖所有分支,Woody参考了catalyst中的LogicalPlanVistor类),找到所有叶子节点,包括:
- Project的project list的每一个元素,
- Join条件的left表达式,right表达式,以及condition表达式,
- Aggregate的grouping 表达式,aggregate表达式,
- Sort的order表达式……
从这些叶子节点过滤得到 UnresolvedRelation类型的节点,这些节点对应的都是source表。
而接下来需要替换的target表,working表,source表或者location信息,均已从当前语句中提取出来,结合当前的context即可进行转换。
转换
接下来需要依据提取到的信息结合当前context进行转换。前面提到ParserRuleContext用于替换,只需要找到需要转换的节点。
那么,哪些节点是可能被替换的呢?
- 表名信息;
- 包含base和field信息的节点,例如语句‘select ta.id from ta’的‘ta.id’, 可能需要替换其中的表名ta部分;
- 表property节点,比如spark data source表property 里面的path就是表的路径,Woody可能需要转换这个路径;
- Location节点。
第三条和第四条,都是为了转换location信息,只需要做一个路径映射即可。
关于第一条:
- 如果该表是source表且没有被alter过,则继续用原表;
- 如果该表是source表,但是被alter过,则使用转换后的表名(参考第一小节:隔离)。
关于第二条包含base 和field信息的节点:
- 这个base表可能是别名不需要转换;
- 这个base表可能是With语句中的temp view,不用转换;
- 参考第一条的转换规则。
除此之外,还有一些场景,无法在一次替换中解决, 比如,一个表可能既是source表又是target表。
insert into ta select ta.* from ta join tb on …
Woody会在完成第一次替换之后才将表ta标记为target表,然后再次替换被insert表的表名为测试表。
而对于以下语句,Woody可以直接跳过该转换部分。
- use database, Woody会在context中改变当前database;
- set/reset/clear cache语句,保留原语句。
此外,Woody在完成job中所有语句转换之后,会去校验context中的所有source表是否含有global view。
由于view只是将一个查询进行封装,底层仍然可能含有source表信息,Woody为了将所有表信息更好地串联起来,会去查询该view的创建语句,然后转换该view的创建语句,直到所有的source表不存在global view为止。
准备
经过前面的语句转换,Woody会直接读取线上表的数据,然后将计算结果输出到测试表中。
Woody会查询metastore, 获取这些测试表对应的线上表的建表语句,然后转换为测试表的建表语句,用于后续的测试前准备阶段。
数据质量校验
进行完测试前准备之后,Woody按照要对比的两个Spark版本,顺序启动两个Spark 应用来运行转换后的语句。在每个版本的Spark运行结束之后去拿到job输出的信息(table count和checksum以及sample),然后对这些输出数据清空复原。在两个版本的Spark应用均运行结束之后,对比其结果,如果结果一致,则代表两个Spark版本的数据是一致的,是兼容的。
校验什么
首先,Woody校验数据有以下几种:
- insert 语句写入的表
- job中创建但是后续没有被使用到的working表
- select语句的结果
前两种场景很好理解,Woody会在语法分析的时候记录这些表,然后在Spark计算任务完成之后,去校验这些表。
关于select
经典的tpc-ds和tpc-h基准测试,都是使用select语句进行,Woody也支持对select语句进行结果校验。
Spark中在缓存(cache)某个RDD的时候,不会立即缓存这个RDD,而是先进行缓存标记,当RDD链触发到这个RDD时才会真正触发缓存操作,Woody对select语句的转换校验也是如此。
首先,Woody在进行语句转换时会识别出哪些语句是select语句,然后用一个计数器计数,先给这个select语句要存入的表分配一个表名,比如WOODY_SELECT_RESULT_{INDEX}。
Woody这样做是因为这个select语句会调用job中其他语句的结果,在转换分析时由于没有真正运行无法拿到该select语句 AnalyzedLogicalPlan, 而无法创建保存这个select结果的表。
在Spark执行这些select语句的时候,Woody会再次识别出这些select语句;然后拿到该select语句的AnalyzedLogicalPlan,从而拿到select结果的schema信息;再根据schema信息,创建用于保存select结果的表;之后再把select语句的结果保存到这个表中,用于后续的结果校验。
如何校验
crc32是一种简单快速的校验算法,通常用于数据传输,它也被用于Hadoop中。Spark中提供了内置函数crc32。该函数的值是Long类型,最大值不会超过10^19。
Decimal是数据库中的一种数据类型,不属于浮点数类型,可以在定义时划定整数部分以及小数部分的位数。对于一个Decimal类型,scale表示其小数部分的位数,precision表示整数部分位数和小数部分位数之和。
一个Decimal类型可以表示为Decimal(precision, scale),在Spark中,precision和scale的上限都是38。因此可以将crc32的值转换为Decimal(19, 0)。
Woody将表中每行的各列数据concat起来,然后计算其crc32,将该crc32转换为Decimal(19, 0)。由于表的count也是Long类型,不会超过10^19,所以每行的crc32值之和不会超过10^19*10^19=10^38,也就是说不会超过Decimal(38, 0)可表示的范围。
在concat表中一行数据的每列数据时,使用‘\u0000’来代表值为空的列,并且每列之间用‘\u0001’隔开。
这样count和checksum就可以有效地表示一个表的检验信息,在获得这个校验信息之后,就可以把当前测试产生的数据清空。
值得注意的是,有些表中含有一些用于审计的列,比如使用current_timestamp来表示更新时间或者current_user来表示是由哪些用户来维护,这些列值会动态变化而且与数据质量无关,业务方提供了这些用于审计的列名,Woody在做checksum的时候会把这些列过滤掉。
使用场景
1. Spark版本升级测试
开发Woody的初衷就是为了让Spark版本升级更加流畅,以减少任务迁移过程中的工作量。Woody支持输入集群名称和成功过的Spark ApplicationId,从而自动拉取job的语句和配置,然后选择需要对比的版本即可进行数据质量对比。
后续会支持账号级别的升级测试,只需要选择用户的账号,Woody即可对该账号需要升级的所有job进行升级测试,测试通过即可将该账号迁移至新版本Spark。
2. Spark-sql job调优
Spark-sql job调优通常分为:
- 参数调优;
- Sql语句调优。
Woody支持在选择Spark版本运行测试时,指定conf或者修改job语句来进行对比测试,用户可以利用Woody来进行job 调优。
3. 端到端测试
前面章节提到的测试都是针对单个job进行的测试。然而线上的Spark-sql job通常是一个job pipeline,包含多个有前后依赖的job。在上线新的job pipleline时,需要进行充足的测试。不仅仅需要benchmark测试,也需要进行仿真测试,用线上的数据来进行测试是一个很好的选择。
但是这需要开发者手动修改job的语句,避免影响线上环境。而人工操作的引入又难免造成误操作,从而导致破坏线上数据,环境等。
针对以上问题,Woody的自动转换线上语句功能就有了用武之地。Hadoop team基于此继续开发,使Woody支持端到端的测试,帮助用户安全的使用线上数据进行测试,而不需要进行任何手动修改工作。
1)串联job
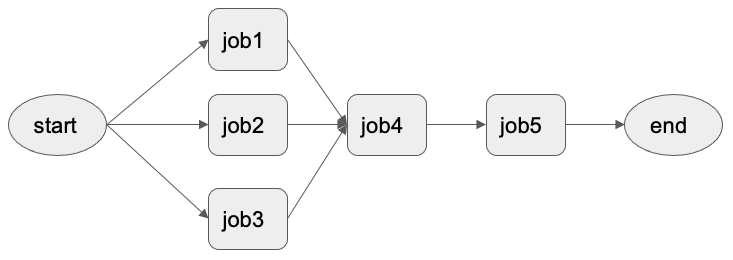
对于单个job来说,转换的context只针对当前job,而针对job pipeline, Woody要将这个转换context扩展为整个 job plan, 要让这个job plan 里面的job联系起来,后面的job要拿前面job的输出作为输入,而不是每次都读取线上的数据作为输入。
eBay内部使用的job pipeline调度框架,对于每个触发的job plan,会分配一个planId传给里面的每个Job, Woody会基于planId 将job pipeline里面的job串联起来。
对于端到端的测试,Woody基于用户的账号来创建一个数据库用于存放job的输出结果,数据库命名规则为pre_prod_{preprod_account}_db;其location为/preprod/{preprod_account}/analysis.db。
将job pipeline进行串联,也就是将前面job的输出作为后面job的输入。
一个job的输出表达有两种:
- 数据写到了哪些表
- 数据写到了哪些路径
关于数据写到了哪些表:
假设表gdw_tables.tba_merge的location 是‘/sys/edw/gdw_tables/tba_merge’,使用b_woody_sub进行测试。如下两条语句:
insert into gdw_tables.tba_merge partition(dt=’20201019‘) select…
alter table gdw_tables.tba set location ‘/sys/edw/gdw_tables/tba_merge/dt=20201019’;
将会被转换为:
insert into preprod_b_woody_sub_db.gdw_tables__tba_merge partition(dt=‘20201019’) select …
alter table preprod_b_woody_sub_db.gdw_tables__tba set location ‘/preprod/b_woody_sub/analysis.db/sys/edw/gdw_tables/tba_merge/dt=20201019’;
Woody在转换第一条insert 语句时候,会将要写入的表名转换为
preprod_b_woody_sub_db.gdw_tables__tba_merge, 而这个转换后的表的location也会被转换为
‘/preprod/b_woody_sub/analysis.db/sys/edw/gdw_tables/tba_merge’,从而Woody得知该insert语句实际写入的location在测试环境里面是‘/preprod/b_woody_sub/analysis.db/sys/edw/gdw_tables/tba_merge/dt=20201019’,
Woody会将这个写入数据的路径记录下来。
在转换第二条AlterTableSetLocation语句时,由于这个被set的location是前面写入过数据的路径,因此,Woody也会知道测试表 preprod_b_woody_sub_db.gdw_tables__tba 被set到了一个被写入过数据的路径,也是一个被写入数据的表。
另外一种情况,如果第一条insert 语句和第二条AlterTableSetLocation语句分别属于两个job,但是有前后关系。
在第一条Insert 语句运行完之后, ‘/preprod/b_woody_sub/analysis.db/sys/edw/gdw_tables/tba_merge/dt=20201019’会被创建出来;
对于第二条AlterTableSetLocation语句,Woody判断得到:
‘/sys/edw/gdw_tables/tba_merge/dt=20201019’ 对应的测试location ‘/preprod/b_woody_sub/analysis.db/sys/edw/gdw_tables/tba_merge/dt=20201019’ 已经存在,也会将 preprod_b_woody_sub_db.gdw_tables__tba 标记为被写入数据的表。
最终Woody会将这个job中所有被写入数据的表跟这个jobPlan 的planId关联起来,存储到mysql数据库中,作为这个jobPlan的context。
在这个jobPlan中的其他job运行时,就可以优先读取这些上游产生的测试数据,而不是去读取线上数据,这样,一条pipeline就可以串联起来。
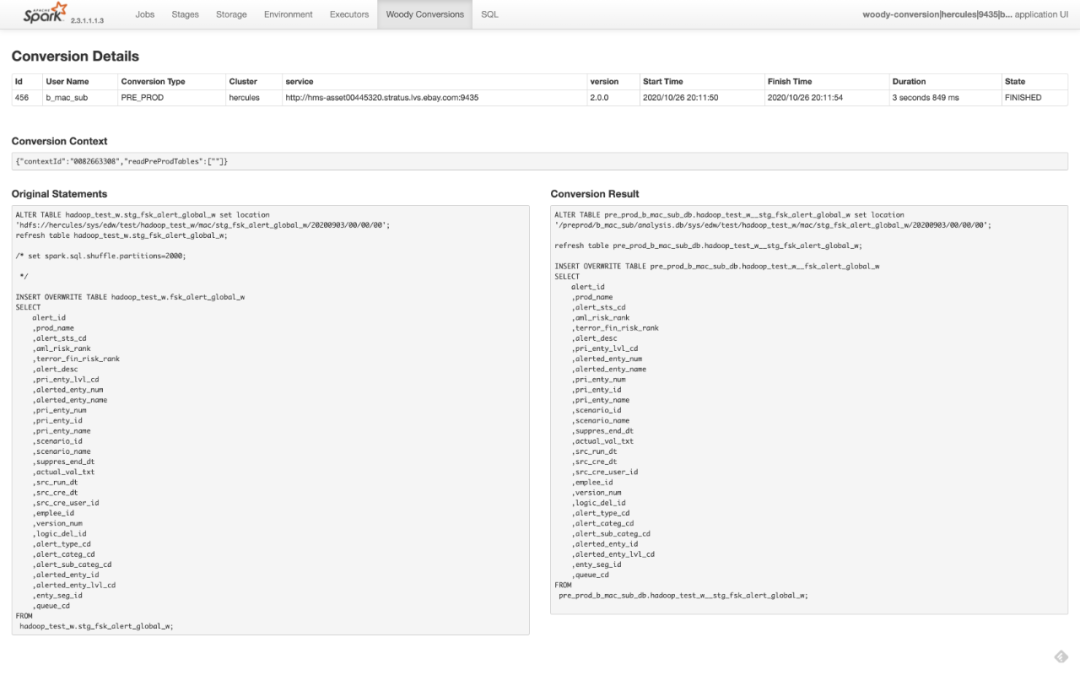
2)转换详情
为Woody开发了conversion history server以及runtime的conversions页面。图6是一个runtime的转换详情页面。
总结
eBay Hadoop team开发的Spark测试框架Woody能够利用LogicalPlan提取job语句中的有效信息,并利用ParserRuleContext进行转换,以线上数据作为输入,将结果输出到测试目录;支持使用不同的Spark版本,conf,甚至修改job sql语句来运行,在运行之后得到数据质量结果和性能比较。总的来说,测试框架Woody的功能主要有以下两个方面:一是用于Spark版本升级及Spark sql job调优,二是用于端到端测试,帮助用户在job pipeline上线之前安全的利用真实的线上数据进行端到端的测试,验证新feature和bug修复,而无需修改任何代码。未来,Hadoop team将进一步优化Woody,以期更好的使用体验。