目录
写点Spark相关的随笔
前言
最近可能比较忙,没有更新博客,写一点Spark相关的随笔。
- 关于bucket table
- 关于解析和更改Spark sql语句
关于bucket table
bucket table是一种Spark常见的优化查询的建表方式。
创建方式是使用clustered by 语法进行创建,会根据spark.sql.shuffle.partitions的值创建若干个bucket。
Spark中对于两个大表的join,采用的方式是SortMergeJoin.
而如果两个表都是bucket表,而且bucket数量相同(业界有公司针对这块的优化,如果两个bucket表bucket数量是倍数关系也可以进行bucket join),那么可以跳过sort(或者加速) 和 shuffle,直接进行join, 会产生较好的性能,通常需要业务方会约定好bucket的数量。
Spark针对bucket表读取的时候,会对每一个bucket分配一个task来读取,因为如果进行bucket join就不能再对这个bucket的数据进行拆分。
但是问题来了,我们并不是每次读取bucket表都是为了进行bucket join,比如说有时候我们会对这个bucket进行etl操作。
如果只是单纯的对这个bucket表进行一些处理操作,例如就是一个单纯的shuffle操作。而这个bucket表的每个bucket都特别大,例如大于1个G,而在shuffle write阶段要生成3G的数据。那么这时候对每个bucket分配一个task来处理就会非常吃力。
其实spark sql中有一个参数 spark.sql.sources.bucketing.enabled,默认是true。如果我们将这个参数设置为false,那么spark就会将一个bucket table看做一个普通的table。
这意味着什么呢?
Spark对于普通表,如果他的单个文件大于一个hdfs block大小(通常是128M),而且这个文件又是可拆分的(例如text文本,snappy 压缩格式的parquet文件等等),那么spark会按照这个文件拆分,分配多个task来处理。
因此,针对我们上面的场景,设置这个参数为false,可以大大的加快map阶段的执行,起到优化的效果。
关于解析和更改Spark sql语句
如果你有对一个Spark sql语句进行解析和更改部分语句的需求。
例如我需求对一条sql中的表名进行映射修改,或者对其中的UDF(其实在spark sql中function 和table 是很类似的东西)和location信息进行修改。
可能首先想到的就是使用正则进行字符串匹配,去寻找自己需要的字段,但是这种方法十分的不靠谱,因为sql的语法十分复杂,我们很难完全准确的抓取到自己需要的信息。
所以我们能不能根据抽象语法树去拿到我们想要的字段呢?
答案当然是Ok的,一条sql语句进行解析器之后都会成为一个抽象语法树,每个TreeNode都有自己的类型,我们可以根据这些类型拿到自己想要的信息,比如table name, function name, location等等信息(table 根据TableIdentifier类型节点获得,function根据FunctionIdentifier, location信息从LoadDataCommand或者CreateTableCommand中获取)。
如下图所以,一条SQL语句INSERT INTO TRABLE tb SELECT ta.id FROM ta JOIN tb on ta.id=tb.id会被大概转化为下面一个AST.
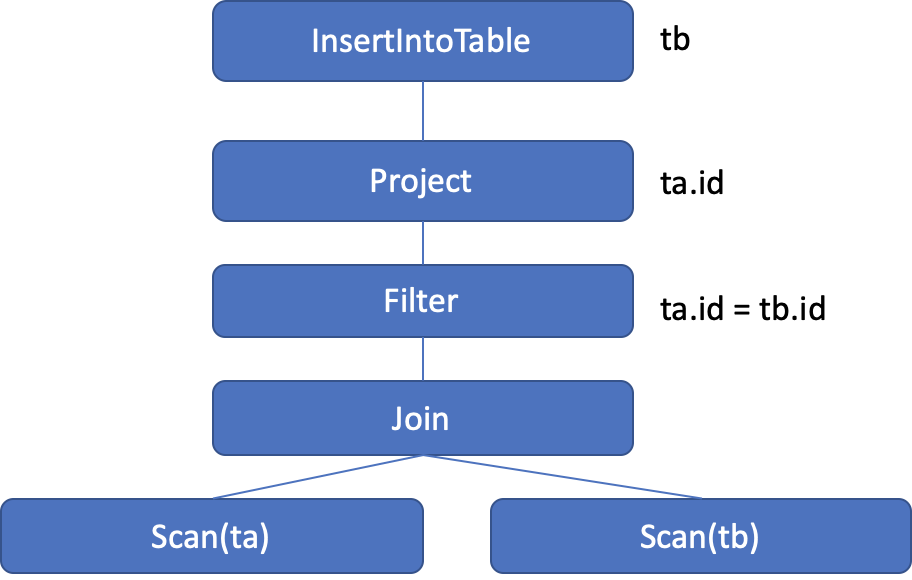
但是,当我们拿到我们想要的信息,之后如何转换想要的SQL呢?
我第一想法是说,直接修改这个AST,然后将这个AST转化为一条SQL语句。但是AST转SQL很麻烦的事情,需要你自己精通sql语法,然后写一套 Plan转String的规则。这听起来就很麻烦。
好在经过一番探索:
- Spark使用antlr v4进行sql解析
- 每个sql最开始解析为一个原始的AST(parsedPlan,未经过analyze/optimize)
- 这个sql也对应一个
ParserRuleContext(packageorg.antlr.v4.runtime)
ParserRuleContext其实也是一棵树,类似于AST,但是它的每个叶子节点会对应一段text,也就是说对应一部分原始的sql语句(table对应TableIdentifierContext,function对应QualifiedNameContext, location对应LocationSpecContext)。
感兴趣的话可以去看这个类的源码: https://github.com/antlr/antlr4/blob/master/runtime/Java/src/org/antlr/v4/runtime/ParserRuleContext.java。
前面我们提到的语句会被转化为下面的一棵树,我这里是将其转为String打印出来,在每个节点处进行了换行。

有了这样的两棵树AST 和ParserRuleContext,我们就可以根据第一棵树,拿到我们想要的信息,然后再在第二棵树上面找到其对应的偏移量。
然后对对应部分进行替换,之后再把第二棵树的碎片对应的文本拼接起来就好了。