目录
本文讲如何在Spark sql Catalyst里面添加自己的Rule,来进行一些优化或者check操作。
前言
前面写过文章介绍Spark Catalyst. 此处再简单介绍下。
在大数据的一些具有SQL功能的框架中,比如Hive,Flink使用Apache Calcite 来做sql的query优化。而Catalyst是spark官方为spark sql设计的query优化框架, 基于函数式编程语言Scala实现。Catalyst有一个优化规则库,可以针对spark sql语句进行自动分析优化。而且Catalyst利用Scala的强大语言特性,例如模式匹配和运行时元程序设计(基于scala quasiquotes),使得开发者可以简单方便的定制优化规则。
一条sql的处理过程
一条sql语句在spark 中会经过以下过程。
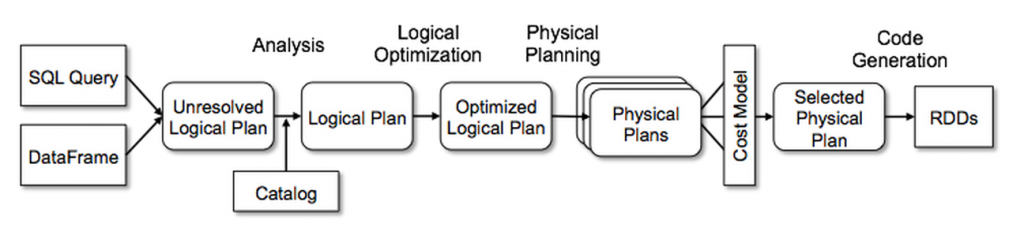
- 首先会通过解析器,将其解析为一个抽象语法树(AST),这叫做unresolvedRelation LogicalPlan。
- 之后进入analysis阶段,可以将其分为几个子阶段
Hints比如BroadcastJoinHints处理Simple Sanity Check简单check,比如检查sql 中的Function是否存在Substitution对sql中的一些进行替换,比如如果union 只有一个child,则取消unionResolution对sql中的一些信息进行绑定,这样就是Resolved LogicalPlanPost-Hoc Resolutionresolution之后的操作,默认是空,用户可以自己注入- 之后还有其他阶段,所以analysis阶段,不止resolution.
- 接下来进行optimization阶段,使用
Rule对LogicalPlan 进行优化,得到Optimized LogicalPlan - 之后是通过使用
SparkStrategy和Rule来将LogicalPlan转换为可执行的物理计划SparkPlan。 - 之后进行codeGen
LogicalPlan是逻辑计划,SparkPlan是物理计划。
Rule
首先,每个阶段都有一个执行计划,可以看成是一个树,树的每个节点是一个LogicalPlan 或者 SparkPlan.
而Rule 就是对树上的每个节点进行transform操作。
abstract class Rule[TreeType <: TreeNode[_]] extends Logging {
/** Name for this rule, automatically inferred based on class name. */
val ruleName: String = {
val className = getClass.getName
if (className endsWith "$") className.dropRight(1) else className
}
def apply(plan: TreeType): TreeType
}
而我们看Rule的apply方法,是将一个TreeType转换为TreeType。
也就是说,它可以将一个LogicalPlan转化为另一个LogicalPlan,或者将一个SparkPlan转化为另外一个SparkPlan。
也就是说Rule不会涉及到质变。
Strategy
Strategy和Rule类似,同样是对树上的节点进行转化操作,但是Strategy是质的改变,它会将一个LogicalPlan转化为一系列SparkPlan。
abstract class GenericStrategy[PhysicalPlan <: TreeNode[PhysicalPlan]] extends Logging {
/**
* Returns a placeholder for a physical plan that executes `plan`. This placeholder will be
* filled in automatically by the QueryPlanner using the other execution strategies that are
* available.
*/
protected def planLater(plan: LogicalPlan): PhysicalPlan
def apply(plan: LogicalPlan): Seq[PhysicalPlan]
}
SparkSessionExtensions
SparkSessionExtensions是用来让用户自己扩展Catalyst 中的Rule, Strategy,甚至自己定义解析规则等等。用户只需要实现自己的Extensions,例如class MyExtensions extends (SparkSessionExtensions => Unit),然后配置spark.sql.extensions=MyExtensions.
首先介绍里面定义的几种type.
// 注入一个Rule
type RuleBuilder = SparkSession => Rule[LogicalPlan]
// 用于check而已,只是check LogicalPlan,如果不通过,会抛异常,通过则不做任何操作,所以返回类型为Unit
type CheckRuleBuilder = SparkSession => LogicalPlan => Unit
// 注入一个Strategy
type StrategyBuilder = SparkSession => Strategy
// 注入一个Parser, 用于语法解析
type ParserBuilder = (SparkSession, ParserInterface) => ParserInterface
这几种类型,是几种方法类型,是用于后面所说的几种方法使用。
我们讲一下里面的几个public方法。
在Analysis阶段的Resolution子阶段添加Rule
def injectResolutionRule(builder: RuleBuilder): Unit
这个方法是添加一个Rule用于resolve unResolvedLogicalPlan。 只需要自己实现一个Rule,然后使用这个方法进行Rule注入。
在Analysis阶段的Post-Hoc Resolution子阶段添加Rule
def injectPostHocResolutionRule(builder: RuleBuilder): Unit
只需要自己实现一个Rule,会在ResolvedLogicalPlan之后,OptimizedLogicalPlan之前执行.
在Analysis阶段之后对LogicalPlan进行check
def injectCheckRule(builder: CheckRuleBuilder): Unit
在Analysis阶段之后对LogicalPlan进行check,如果有问题,则抛异常。没问题则检查通过。
需要自己实现CheckRuleBuilder.
注入自己的Optimizer Rule
def injectOptimizerRule(builder: RuleBuilder): Unit
注入自己的Strategy
def injectPlannerStrategy(builder: StrategyBuilder): Unit
注入自己的解析器
def injectParser(builder: ParserBuilder): Unit
如何使用
case class MyResolutionRule(spark: SparkSession) extends Rule[LogicalPlan] {
override def apply(plan: LogicalPlan): LogicalPlan = plan
}
case class MyPostHocResolutionRule(spark: SparkSession) extends Rule[LogicalPlan] {
override def apply(plan: LogicalPlan): LogicalPlan = plan
}
case class MyOptimizerRule(spark: SparkSession) extends Rule[LogicalPlan] {
override def apply(plan: LogicalPlan): LogicalPlan = plan
}
case class MyCheckRule(spark: SparkSession) extends (LogicalPlan => Unit) {
override def apply(plan: LogicalPlan): Unit = { }
}
case class MySparkStrategy(spark: SparkSession) extends SparkStrategy {
override def apply(plan: LogicalPlan): Seq[SparkPlan] = Seq.empty
}
case class MyParser(spark: SparkSession, delegate: ParserInterface) extends ParserInterface {
override def parsePlan(sqlText: String): LogicalPlan =
delegate.parsePlan(sqlText)
override def parseExpression(sqlText: String): Expression =
delegate.parseExpression(sqlText)
override def parseTableIdentifier(sqlText: String): TableIdentifier =
delegate.parseTableIdentifier(sqlText)
override def parseFunctionIdentifier(sqlText: String): FunctionIdentifier =
delegate.parseFunctionIdentifier(sqlText)
override def parseTableSchema(sqlText: String): StructType =
delegate.parseTableSchema(sqlText)
override def parseDataType(sqlText: String): DataType =
delegate.parseDataType(sqlText)
}
class MyExtensions extends (SparkSessionExtensions => Unit) {
def apply(e: SparkSessionExtensions): Unit = {
e.injectResolutionRule(MyResolutionRule)
e.injectPostHocResolutionRule(MyPostHocResolutionRule)
e.injectCheckRule(MyCheckRule)
e.injectOptimizerRule(MyOptimizerRule)
e.injectPlannerStrategy(MySparkStrategy)
e.injectParser(MyParser)
}
}
In Action
首先介绍下Spark-greenplum项目,这是一个针对于greenplum(一种数据库)的一个DataSource实现。
其使用PostgreSql的COPY命令进行数据写入,相对于JDBC DataSource(通用的操作数据库的DataSource)的分批insert数据性能提升可观。
而在spark-greenplum中,如果我们 使用先建立TEMPORARY TABLE然后Insert数据的方法操作gp.
CREATE TEMPORARY TABLE tbl
USING greenplum
options (
url "jdbc:postgresql://greenplum:5432/",
delimiter "\t",
dbschema "gptest",
dbtable "store_sales",
user 'gptest',
password 'test')
INSERT INTO TABLE tbl SELECT * FROM tpcds_100g.store_sales WHERE ss_sold_date_sk<=2451537 AND ss_sold_date_sk> 2451520;
首先,我们需要建立一个gp 表,然后在spark sql中创建 TEMPORARY TABLE, 这个临时表的schema是和gp表中的schema一样的。
之后,我们使用Insert语句将子查询中的列插入到这个临时表,也就是写入到对应的gp表中。
这时候我们通常需要判断SELECT SUB Query中拿到的列是否和临时表中的列对应一致。
所以我们选择添加一条CheckRule来实现,也就是调用injectCheckRule方法。
实现如下:
import org.apache.spark.internal.Logging
import org.apache.spark.sql.{AnalysisException, SparkSession, SparkSessionExtensions}
import org.apache.spark.sql.catalyst.plans.logical.{LogicalPlan, Project}
import org.apache.spark.sql.execution.datasources.{InsertIntoDataSourceCommand, LogicalRelation}
import org.apache.spark.sql.execution.datasources.greenplum.GreenplumRelation
case class GreenPlumColumnChecker(spark: SparkSession) extends (LogicalPlan => Unit) with Logging {
override def apply(plan: LogicalPlan): Unit = plan match {
case InsertIntoDataSourceCommand(LogicalRelation(_: GreenplumRelation, output, _, _),
Project(_, c), _) =>
// The real output of sub query, which is not be casted.
val realOutput = c.output
if (realOutput.size != output.size || realOutput.zip(output).exists(
ats => ats._1.name != ats._2.name)) {
throw new AnalysisException(
s"""
| The column names of GreenPlum table are not consistent with the
| projects output names of subQuery.
""".stripMargin)
}
case InsertIntoDataSourceCommand(LogicalRelation(_: GreenplumRelation, _, _, _), query, _) =>
query.
logWarning(s"GreenPlumColumnChecker: The query of this GreenPlumRelation " +
s"is a ${query.getClass.getName}.")
case _ =>
}
}
class GreenPlumColumnCheckerExtension extends (SparkSessionExtensions => Unit) {
override def apply(e: SparkSessionExtensions): Unit = {
e.injectCheckRule(GreenPlumColumnChecker)
}
}
PS: Spark-2.3.2只能指定一个spark.sql.extensions,可以合入PR-26493来支持多个extensions.